Quick Links:
Lectures:
Last updated at 05:30 PM on 19 Jan 2010
Overview
This page provides supplementary information to support lectures in ME 488 during Fall 2009. The notes are presented in reverse chronological information, i.e. the most recent lecture is listed first.
Here is a short list of books, in addition to the textbook we are using for the course, that I consult when preparing notes or attempting to reduce my own confusion of some aspect of DOE.
-
Box, George E. P., Hunter, Stewart, J., and Hunter, William G.,
Statistics for Experimenters: Design, Innovation, and Discovery
2nd ed., 2005, Wiley-Interscience.
This is a classic DOE book, but not the best for the beginner who is looking for recipies. BHH provide ample computational formulas, but their approach is to motivate understanding through case studies that illustrate points and counterpoints. -
Mathews, Paul, Design of Experiments with MINITAB,
2005, ASQ Quality Press, Milwaukee, WI.
As its title suggests, this book demonstrates DOE calculations with MINTAB. However, this is a textbook, not a cookbook. Mathews attempts to provide a broad exposition of applied statistics as well as the computational aspects of statistics, and in particular, MINTAB. -
Montgomery, Douglas G., Design and Analysis of Experiments,
5th ed., 2001, Wiley, New York.
This is a modern textbook that covers a large swath of DOE. Many case studies are provided. The seventh edition is the latest.
If you could only afford one of these books (and they are expensive), I would consider finding a used copy of Montgomery. The current edition sells for $130 at Amazon (Nov. 2009). The second book should be Box, Hunter and Hunter. Both of those books should be available at a library.
Lecture Notes
9. Factorial Designs, Using MINITAB for two-level, two-factor and two-level three factor ANOVA
Lecture on 23 November 2009
Reading: pp. pp. 513 -- 523
Homework: TBA
Learning Objectives
- Be able to define a factorial experiment.
- Be able to explain at least one positive consequence of using replicates for a two-level two-factor ANOVA.
- Be able to identify at least negative positive consequence of not using replicates for a two-level two-factor ANOVA.
- Be able to use MINITAB to perform two-level, two-factor and three-factor ANOVA with interactions.
Notes on Using MINITAB
Download the MINITAB Instructions as MS Word or PDF
Download the Laundry2.txt and Laundry3.txt data files.
6. Power of a hypothesis test; Selecting sample sizes; Introduction to two-factor ANOVA
Lecture on 9 November 2009
Reading: pp. 395 -- 398 (review), pp. 513 -- 523
Learning Objectives
- Be able to define type 1 and type 2 errors for hypothesis testing.
- Be able to define Power of a hypothesis test.
- Be able to use MINITAB to compute sample sizes for various tests given a desired alpha, delta, and beta.
- Be able to describe what is being compared in a two-way ANOVA calculation.
- Be able to list the conditions that must be met for a two-factor ANOVA to be appropriate.
- Be able to identify the components (terms and sums) that go into a two-factor ANOVA
Type II Errors:
Class notes on Type I and Type II errors are more extensive than pp. 395 - 398 in the textbook. The following image shows two possible outcomes for a hypothesis test on a population mean with the standard deviation is known. [The image is from Paul Mathews, Design of Experiments with MINITAB, 2005, ASQ Press, Milwaukee, p. 86]
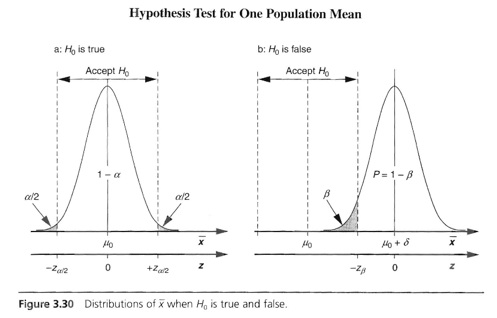
![[Click for Larger Version]](./png/H0_true_and_not_true.jpg){kind=link}
Selecting Sample Sizes
The textbook does not describe procedures for selecting the sample size to obtain a desired power.
General Procedure
To choose a sample size to obtain a desired power, you will need to use a procedure that is specific to the hypothesis test. The following procedure is generic.
- Identify the desired sensitivity, delta
- Assume a value for the population variance
- Choose a significance, alpha
- Choose a power (or value of beta --> P = 1 - beta)
- Compute n
With MINITAB
Use the Stat menu:
Stat --> Power and Sample size --> [desired hypothesis test]
Other sources of information
Today's lecture notes were created from several references. The example of how beta arises in a test of population means was taken from Paul Mathews, Design of Experiments with MINITAB, 2005, ASQ Press, Milwaukee, WI [Link to Google Books], [Link to Amazon]
The following list provides links to free, on-line references.
- Professor Russ Lenth's Java Applets for Power and Sample Size Calculation
- HyperStat Online: many links to Power analysis
- List of software for Power and Sample Size calculation University of California, San Francisco: Division of Biostatistics
- Dave Thompson's page on Hypothesis testing and statistical power.
Two-way ANOVA in MINITAB
See pp. 513 - 523 in the textbook
Also from Paul Mathews, Design of Experiments with MINITAB (Section 6.7, p. 215): Two-way ANOVA can be performed in MINITAB via three different menus
-
Stat --> ANOVA --> Two-way
This is the simplest to use, but it also has the fewest options.
-
Stat --> ANOVA --> Balanced ANOVA
This method has more options that the preceding method, but the analysis is limited to balanced (equal number of observations for all levels of all factors) and full-factorial designs.
-
Stat --> ANOVA --> General Linear Model
This has the most options, and it provides the capability to do post-ANOVA multiple comparisons.
4. Randomization of Test Sequences; One-way ANOVA
Lecture on 19 October 2009
Reading: pp. 367 --374 (review), pp. 398 -- 412
Learning Objectives
- Be able to describe why randomizing the order of experiments is important.
- Be able to use manual and computer-based techniques to randomize the order of experiments
- Be able to describe what is being compared in a one-way ANOVA calculation.
- Be able to list the conditions that must be met for a one-way ANOVA to be appropriate.
- Be able to perform a one-way ANOVA by hand (assuming sums of terms are provided), including applying the appropriate F-test.
- Be able to use MINITAB to perform a one-way ANOVA
- Be able to interpret the results of the MINITAB output for a one-way ANOVA
ANOVA in a Nutshell
After class I created a short set of slides that lists the main calculation formula in a one-way ANOVA.
Excel freak out
During class my attempts to demonstrate the randomization of data and (later) a "manual" ANOVA calculation were thwarted by mysterious behavior of Excel. Several important commands from the ribbon bar were simply not responding to mouse clicks.
with a completed ANOVA calculation
MATLAB Calculations
The randomizeDemo code listed below shows how you can randomize the order of tests
with MATLAB. Note that the randomize function works
with any vector of test values, so it can be reused in other projects.
You can
download the randomizeDemo.m function.
The one-way ANOVA of the cotton thread data is computed with the following MATLAB codes and CSV data file
ANOVAdemo.m
fp.m(StatBox)
fq.m(StatBox)
betaq.m(StatBox)
Montgomery_Cotton_Data_set.csv
The fp, fq, and betaq
functions are from the
StatBox toolbox.
randomizeDemo.m
function randomizeDemo % randomizeDemo Example of randomizing the order of a single-factor test % Use example problem from data from D.C. Montgomery, % Design and Analysis of Experiments, 5th ed., 2001, % Wiley, New York. See Chapter 3, pp. 60-62 % % No inputs to the main program% -- Set up the trial data nreps = 5; % number of repetitions per treatment reps = ones(1,nreps); % Temporary vector to create list of treatments
% -- CWP is the Cotton weight percents, SID is a list of labels (IDs) CWP = [ 15reps, 20reps, 25reps, 30reps, 35*reps]; SID = 1:length(CWP);
% -- Randomize the test order [CWPrand,SIDrand] = randomize(CWP,SID); fprintf('n Test Sample Cotton WeightnSequence ID Percentn'); for i=1:length(CWPrand) fprintf('%4d %6d %6dn',i,SIDrand(i),CWPrand(i)); end
% =============================================== function [xrand,idrand] = randomize(x,id) % randomize Randomize a vector of test conditions x with corresponding IDs % % Synopsis: xrand = randomize(x) % [xrand,idrand] = randomize(x) % [xrand,idrand] = randomize(x,id) % % Input: X = vector of values to be put in random order % id = optional vector if IDs for the x data % % Output: xrand = values of the x vector in random order % idrand = optional vector of ID values for to the elements in x % If no id vector is supplied, but idrand is expected as % a return value, generate the IDs as sequential integers
% -- Generate a random vector, sort it, and save the sort order. irand = randperm(length(x)); % randomized list of integers [junk,isort] = sort(irand); % isort is the sort order for the integers xrand = x(isort);
% -- Sort IDs if user either supplies IDs or asks for IDs if nargin>1 idrand = id(isort); % If IDs were supplied, sort them too elseif nargout>1 % No IDs were supplied, generate some & then sort id = 1:length(x); % Generate sequential IDs idrand = id(isort); % and sort them in the same order as xrand end
3. Review of Confidence Intervals and Hypothesis testing
Lecture on 12 October 2009
Reading: pp. 367 --374 (review), pp. 398 -- 412
Learning Objectives
- Be able to identify the standard error term for calculating confidence intervals on the mean
- Be able to explain why the standard error depends on the sample size.
- Be able to perform a t-test for the comparison of two means using different assumptions about the variances of the population(s)
F-test
We didn't get to the F-test, but you can download my notes.
2. Review of Confidence Intervals and Hypothesis testing
Lecture on 5 October 2009
Reading: Chapter 9
Learning Objectives
- Be able to describe the differences and similarities between the standard t distribution and the standard normal distribution
- Be able to read critical values of the t-distribution from the reference table in Appendix A of the textbook
- Be able to compute confidence intervals on the mean of a population
- Be able to perform a t-test for the comparison of two means
Confidence Interval for Estimation of the Mean
Read Chapter 8, paying attention to section 8.3. The computational formula is in Equation 8.2 on page 373.
Key points:
- The t distribution describes the probability of a normally distributed random variable when the sample size is small
- The mean of the sample is a computed statistic
- The standard deviation of the sample, s, is a computed statistic
- The number of degrees of freedom is n-1, where n is the number of values in the sample
- You choose the level of confidence, alpha
- Look up the critical t-value from Table A.4
- Compute the width of the confidence intervals with t(n-1)(s/sqrt(n))
Basic Outline of Hypothesis testing
On pages 400-401, Levine et al list the steps in Hypothesis testing. A more compact list from Ayub and McCuen, was discussed on class. The Ayub and Mccuen list is presented here (without all of the documentation)
- Form a Hypothesis: Define the null and Alternative Hypothesis
- Determine the test statistic and the appropriate distribution
- Choose the level of significance
- Data analysis
- Design the experiment
- Perform the measurements
- Compute descriptive statistics
- Define the region of rejection (one or two-tailed) which determines the critical (or cut-off) values of the test statistic
Example: Comparing morning and afternoon measurements of blood pressure
The solution to the Comprehensive Problem on Problem set #1 was presented in class.
1. Introduction, Review of Statistics, Introduction to MINITAB
Lecture on 28 September 2009
Learning Objectives
- Know how to contact GWR: email, telephone, office hours
- Review highlights of descriptive statistics, inference and hypothesis testing
- Be able use MINITAB to compute basic descriptive statistics
Handouts
I didn't hand it out, but I displayed the ME 488 calendar for Fall 2009
Commuting Data
At the end of class I began a MINITAB demonstration of analyzing my commuting time data. The two data files are commuteTimesHomeToPSU.csv and commuteTimesPSUToHome.csv
Textbook Reading
It is important that you remember your basic statistics. Accordingly you should review Chapters 1, 3, and 5 from the textbook.
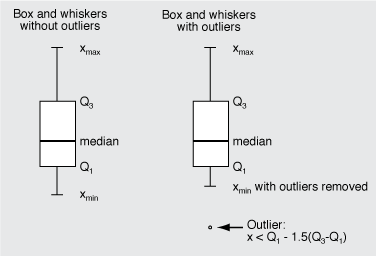
Outliers
While doing the homework, a student asked about outliers.
An outlier is a value in a sample that is significantly different from other values in that sample. Treatment of outliers can be problematic. A normal distribution contains all values from minus infinity to plus infinity. Values in the tails of the distribution are not likely to be observed, but they exist.
What should you do when you have a sample (i.e. a finite set of values drawn from a population) that contains one or more values that don't seem to belong? If you include the outlier(s), the sample statistics will have a larger dispersion (larger variance, larger inter-quartile range, etc.) than if the outliers are excluded. However, should you eliminate the outlier just to make your data look good?
The following discussion only applies to the display of data with a box-and-whisker plot. We will need to separately address the treatment of outliers in the analysis of data.
In a box-and-whisker plot, outliers are defined in terms of the inter-quartile range, IQR = Q3 - Q1, where Q1 is the first quartile of the sample and Q3 is the third quartile. The outliers are identified by symbols (circles or asterisks) that lie beyond the range of the whiskers. This is just a convention and only affects the display of the data.
In a box-and-whisker plot, an outlier is defined as follows
Greater than Q3 + 1.5×IQR
or
Less than Q1 - 1.5×IQR
If outliers are identified by either of these criteria, then xmax and/or xmin are recomputed. The rules for identifying outliers (in the box-and-whisker) plot are not applied recursively, i.e. once the outliers have been identified and xmax and/or xmin are recomputed, the test for outliers is not applied again.
The following diagram is a summary of the box-and-whisker symbols for data with and without outliers. This diagram differs in its appearance from a MINITAB plot with outliers, but the basic layout is the same.