Portland State University
Standard video frame interpolation methods first estimate optical flow between input frames and then synthesize an intermediate frame guided by motion. Recent approaches merge these two steps into a single convolution
process by convolving input frames with spatially adaptive
kernels that account for motion and re-sampling simultaneously. These methods require large kernels to handle large
motion, which limits the number of pixels whose kernels can
be estimated at once due to the large memory demand. To
address this problem, this paper formulates frame interpolation as local
separable convolution over input frames using pairs of 1D kernels. Compared to regular 2D kernels,
the 1D kernels require significantly fewer parameters to be
estimated. Our method develops a deep fully convolutional neural network that
takes two input frames and estimates pairs of 1D kernels for all pixels
simultaneously. Since our method is able to estimate kernels and synthesizes
the whole video frame at once, it allows for the incorporation of perceptual loss to train the neural network to produce visually pleasing frames. This deep neural network is trained
end-to-end using widely available video data without any
human annotation. Both qualitative and quantitative experiments show that our method provides a practical solution
to high-quality video frame interpolation.
IEEE ICCV 2017. PDF Code
Note: After the publication of our paper, we recently found that the idea of estimating spatially-varying linear filters to transform an image for many computer vision tasks was explored by Seitz and Baker in their ICCV 2009 paper "filter flow". It would have been nice to cite and discuss their "filter flow" paper in our work. We encourage others to cite Seitz and Baker if your work builds upon the idea of estimating spatially-varying linear filters for image transformation / synthesis.
IEEE CVPR 2018. PDF
Simon Niklaus, Long Mai, and Feng Liu. Video Frame Interpolation via Adaptive Convolution .
IEEE CVPR 2017. PDF Project Website(spotlight)
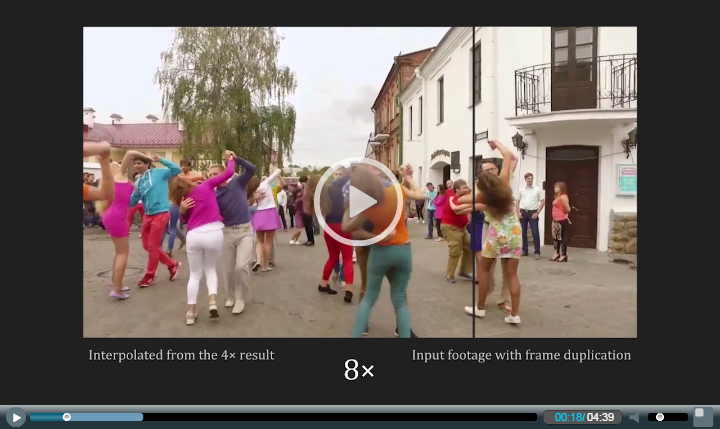
This work was supported by NSF IIS-1321119. This video uses materials under a Creative Common license or with the owner's permission, as detailed at the end.