Simple Data
Types
CS 161:
Introduction to Computer Science 1
const Type qualifiers
• The const type qualifier exists in C++. If you precede a variable declaration with the word "const" then it just means you've made a constant and that its value does not change! You are not allowed to directly change the value of a constant. If you try to change a value of a constant indirectly through a pointer - the results are implementation dependent!
• You can use a const specifier to "freeze" the value of an entity within its scope. This allows you to freeze the data pointed to, an address, etc. When you declare a constant, it must be initialized because it cannot be assigned later on. Using a constant ensures that the value will not change within its scope.
const int atest = 90;
atest = 100; // this would be illegal!
This improves readability by allowing descriptive names to be used in the same place of a less-descriptive literal.
The const specifier can also be used with function parameters. This is a nifty addition that C++ has over C (since we can declare our variables & constants anywhere in the program):
void print_curve(const int value) {
cout <<value <<endl;
}
But, the following would be illegal (notice that using const for a parameter value makes it illegal for the body of the function to reassign the parameter to a new value. It is useful when you don't want a function to be able to muck with the values of the parameters; it is also useful since it allows compilers to perform better code optimization.):
void print_curve(const int value)
{
value = 45;
cout <<value <<endl;
}
Would result in a warning that
a read-only location is being reassigned; some compilers would give an error (error messages are probably more common
here).
C++ Declarations
• Remember that in C++ every identifier, constant, and expression has a type. The type determines the operations that may be performed on your data. Declaration statements introduce variables into your program...specifying type followed by the name (or list of names) of the variable(s). Before a variable can be used in your program, it must be declared.
• We must make sure to distinguish the difference between a declaration and a definition: a variable declaration specifies the properties of the variable (i.e., its type and name); a variable definition specifies the properties of the variable AND causes storage to be set aside (and can also set an initial value to the variable).
• In most cases, declarations are also definitions. This is because you not only associate a type with a variable name, but you also allocate the memory and give the variable an initial value.
• Variables can be initialized when they are defined. For example:
int variable1 = 100;
• Now...in addition to what we already understand, C++ enhances these capabilities. Declarations can now be made within blocks of code ... even after code statements! A declaration can be made anywhere a statement is allowed. This allows you to declare an entity closer to its first point of application. It also allows an index to be declared within a loop, for example:
for (int i=0; i< 12; i++)
{
int j = i;
...
}
Types and their representation
• The following is a useful diagram of the fundamental data types:
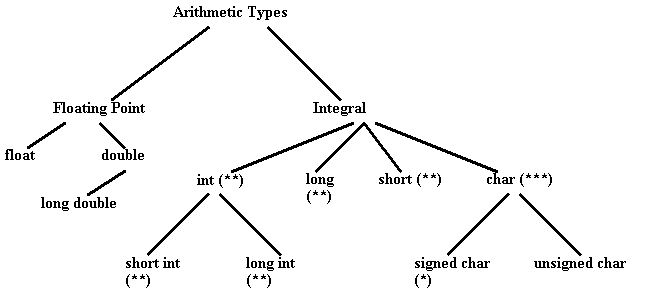

int
• The int data type is probably the most common and represents the word size of your machine. It is important to realize that int is not the same size on all machines. For example, an int is the same as a long -- but on other systems an int might be the same as a short. Notice how dangerous this might be when thinking about portability! And, to top it all off, when an int overflows or underflows -- it just wraps around; this means that you may not be able to accurately predict the results of your program when expecting an int to be the same as a long - when in fact it might be the same as a short!
• How do we resolve this? Explicitly use short to save memory and long when expecting the full 32 bits.
• Generally, an int is the largest efficient integer...so if efficiency is more important to you than portability, then use int instead! An int is generally the size of a "word" on your machine. On a 16-bit machine, it is 16 bits; on a 32-bit machine it is 32 bits.
• Rules for int specify that they cannot be shorter than a short or longer than a long!
short
• short is never longer than a long. C++ guarantees that a short is at least 16 bits.
long
• On many systems a long is twice the size of a short. On rigel, this is true; furthermore, a long and an int are the same size on rigel.
• C++ guarantees that a long is at least 32 bits. It is never shorter than a short.
unsigned integers
• Unsigned integers range from 0 to some maximum, depending on the size of the type requested. For example, they range on our system from 0 to 4,294,967,295! The following are some examples (the word int is optional!):
unsigned short int var1;
unsigned int var2;
unsigned long int var3;
Unsigned values are always represented from 0 to 2n-1. And, unsigned values wrap around, so adding 1 to the largest unsigned number will always give you zero, no matter what architecture you are working on!
• Warning: When using unsigned integers with signed integers, there is a conversion problem that just might bite you! Expressions that mix the two end up being forced to use unsigned operations. So, even though you would expect the following to always be TRUE, it is instead always FALSE!
float, double, long double
• Floating point types are used instead of integral types when additional range is required or when the numbers to be represented have a fractional part. Remember that floating point numbers do not, in general, represent numbers exactly...they have limited precision. Integers, on the other hand, represent numbers exactly, but have limited range.
• Float is the smallest floating point type. It is typically represented in 32 bits. Double is generally twice the size of a float and gives additional range and precision. Long double, if available, gives additional range and precision over a double.
• When using floating points types for computation, be careful to use the smallest type that will adequately represent your numbers ... as operations on the longer types can be very time consuming!
void
• Void is not a type per se, but rather is used to indicate that a function does not return a value.
sizeof
• The sizeof keyword is a compile time operator that results in the size of a type. This size is given as the number of character variables (bytes) that the type occupies. The operand of the sizeof operator can be a type name or a variable or expression. If a variable or expression is given, the resultant value is the size of the type of the variable or expression. Consider the following example:
#include <iostream.h>
main()
{
int i;
cout << "The size of an int is: " << sizeof(int) << "\n";
cout << "The size of 6*7 is: " << sizeof(6*7) << "\n";
cout << "The size of i is: " << sizeof(i) << "\n";
cout << "The size of a double is: " << sizeof(double) << "\n";
cout << "The size of 3.14159 is: " << sizeof(3.14159) << "\n";
}
% a.out
The size of an int is: 4
The size of 6*7 is: 4
The size of i is: 4
The size of a double is: 8
The size of 3.14159 is: 8
Operators, Expressions, and
Statements
• There are two broad categories of fundamental data types: integral (also called ordinal) and floating point. Constants and variables of these fundamental types are used as the operands of operators to compute new values. Some operators apply only to integral types; other operators apply to both types. When an operator applies to more than one type of data it is said to be "overloaded". That means that the operation performed depends on the types of the associated operands.
• For example consider the following statements:
int i,j;
double f,g;
i = i * j; // The * operator performs integer multiplication because
// the type of the two operands are both integer
f = f * g; // The * operator performs floating point multiplication
// (a very different operation than integer multiplication)
// because the type of the two operands are both double
• A constant, variable, or operator and it's associated operands are the building blocks of expressions . All expressions in C++ have an associated type and value (called the residual value). In the case of constants or variables, the residual value is the value of the constant or variable. In the case of an operator and associated operands, the residual value is the result of applying the operator to the associated operands. If the operands are of different types, standard conversions take place so that the operator operates on only one type. We will discuss those standard conversions next.
• An expression becomes a statement in C++ when it is terminated by a semicolon.
C++ Type Conversion
• You can intermix variables/literals of the fundamental types as much as
you'd like in assignment statements and expressions. C++ converts values
implicitly, trying not to loose information. However, there are times when the
implicit manner of type conversion is not satisfactory.
• In C++, the name of a type can be used in the same way as a function to accomplish type conversion. For example, to convert from an integer to a float you can simply say:
int i = 20;
float real = float(i);
Or, we use type casting which would have looked like:
int i = 20;
float real = (float) i;
Both ways can be done in C++, but the first style is "more" natural.
• Before we continue, let's quickly look at the implicit type conversion rules outlined for C++:
(a) If a long double is used as an operand, the other operand is converted to a long double; if neither operand is a long double then...
(b) If a double is used as an operand, the other operand is converted to a double; if neither operand is a double then...
(c) If a float is used as an operand, the other operand is converted to a float; if neither operand is a float then...
(d) It is assumed that we are not dealing with floating point numbers; but we continue checking...
(e) If an unsigned long int is used as an operand, then the other operand is converted to an unsigned long int; if neither operand is an unsigned long int then...
(f) If a long int is mixed with an unsigned int, then the other operand is converted to a long int or both are converted to unsigned long int; if a long is not mixed with an unsigned int then...
(g) If a long int is used as an operand, then the other operand is converted to a long int; if neither operand is a long then...
(h) If an unsigned int is used as an operand, then the other operand is converted to an unsigned int; if neither operand is an unsigned int then we assume both operands are of type int.
(i) chars and shorts are always converted to ints.
C++ Enumeration types
• Enumeration types are provided by most programming languages to improve the readability of your programs. It allows you to assign names to things instead of having to use code numbers.
• For example:
enum weekend {saturday, sunday};
• An enumeration type is just a list of identifiers that denotes the values that constitute the data type. These identifiers are used as constants in the program.
• You can then define variables to be of type weekend:
weekend vacation;
vacation then contains 2 values.
You can say: vacation = saturday; or, vacation = sunday;
However, saying vacation = monday would give you an error "monday undefined"!
• You can test the value of the variable by using the enumeration names:
if (vacation != saturday)
cout <<" I
can't go...I have to work! ";
else
cout <<" Lets
go!!";
• Don't confuse enumeration types with character strings. You should NOT surround enumeration identifiers with quotes! They are simply names -- they are not numbers, characters, or strings.
• The name of an enumeration is a type name. This means that the type of an enumerator is the type of its enumeration in C++; (whereas, the type of an enumerator is an int in C). Since enumerations are distinct types, variables of one enumeration type can only be assigned values of that type. This is a big improvement over C. Let's look at an example:
enum
cmycolor {cyan, magenta, yellow};
enum
rgbcolor {red, green, blue};
rgbcolor
brick = red; // this is legal
rgbcolor
sky = cyan; // warning: type mismatch
Using Abstraction to Manage Complexity
• As we go thru the series of courses starting with CS161 and continuing through CS162 and CS163, abstraction will become an increasingly important concept. In addition, for those of you who plan to become computer scientists & programmers...knowing & becoming proficient with the popular object oriented programming languages will mandate that you thoroughly understand the concept of abstraction.
• So far, we have learned about functions and the concept of procedural abstraction. This was the process of separating the properties of each procedure from one another -- so that once a procedure was created and thoroughly tested, we could forget about how we did the implementation and only be concerned with WHAT the procedure does (and its interface & side effects). Procedural abstraction is separating the WHAT is to be achieved by a procedure with the HOW it is performed.
• C++ enhances your ability to perform procedural abstraction by providing ways to create separate files of functions that can be included in programs using compiler directives. Using this approach, you can create a function once and then re-use it time and time again. Once it is created and tested, you no longer have to recompile such procedures and you can "encapsulate the procedure" with other procedures that are your own. Then, all you need to do is import that procedure when you want to use it...in any of your programs. This is a TRUE separation of HOW you implemented the function with WHAT the function is & provides.
The need for Software Engineering
• Programming projects are many times very complex tasks involving multiple programmers and many 10s of thousands of lines of code. This requires not only good team spirit but also good team programming skills. To do this...we must learn the fundamentals of software engineering. Software engineering helps to ensure that the software is designed efficiently, is reliable, and is easy to use and improve.
• Software systems developed must be reliable (35 to 50% of all software costs are spent on debugging code)...in many cases with software being widespread in automobiles, aircraft, air traffic control systems, and defense systems -- our own lives may depend on the correction operation of YOUR software!!! Think about it!
• Plus, it really isn't enough that software works correction. With the rate that products are changing -- software always demands improvement! So, big programs need to be designed where such improvements can be done without having to recreate or rewrite the entire program (especially when the program might consist of 10,000 lines of code - whew!).
• Software engineering consists of 6 stages -- some of which we learned about in general in the last class.
The first stage is planning. This is where you determine what the need is for the software and estimate how many people it will take to create the software and how long it will take. This is where the cost of the development is estimated and a rough schedule predicted. This phase is necessary to determine if the project is going to even be cost effective for the company/government to undertake. This takes cooperative team effort between corporate executives, software programmers, and the customers.
The next stage is requirements analysis and specifications. This is where a detailed specification for the overall function of the software is created. What is its goal? How will it work? What is its input? What is the output? How compatible should it be with other software? What hardware must it be required to work on? What should the user interface look like? How much memory can it use? What language should it be written in? Who are the customers? What kind of manuals are needed? What are the plans for future features---evaluate how important this is to the product....etc.
Then comes the software design phase. This is where the software program(s) are designed to meet the specifications. The overall software "package" should be broken down into modules with each assigned to a programming team. Each module should be designed -- using pseudo code and desk checked to see if it properly solves its purpose.
Once the skeletons of each module are written and tested and work properly from one module to another, the coding phase can start. This is where the program segments of the modules are written in the specified programming language. If you do a good job with the design phase, the coding phase should be relatively straight forward!
Next comes the validation phase. This is where the software is tested to make sure it works as specified. First each module should be tested. Then as the modules are hooked up together -- the integration of them is tested. Finally, the entire package is tested in relation to the original requirements.
The last phase is maintenance. This involves continual update of the software for bug fixes or to add features. To make sure software is maintainable, it should not only be complete, but you should make sure your code is readable with correct documentation. This will greatly assist programmers in locating, identifying, and repairing software errors (called bugs!).
• In large computing centers, maintenance consumes usually more than half of the software budget! Amazing! No wonder software engineering procedures were developed. Before them -- spaghetti code was the rage......
CS 161:
Introduction to Computer Science 1
1. What is the output of the following program segment?
int main()
{
int sort(int n, int m);
int a,b;
cout <<sort(1,2) <<endl;
cout <<sort(100,500) <<endl;
cout <<sort(650,10) <<endl;
return 0;
}
int sort(int n, int m)
{
if (n < m)
return m;
else
return n;
}