Garbage Collection (GC) is the automatic reclamation of heap records that will never again be accessed by the program.
GC is universally used for languages with closures and complex data structures that are implicitly heap-allocated.
GC may be useful for any language that supports heap allocation, because it obviates the need for explicit deallocation, which is tedious, error-prone, and often non-modular.
GC technology is increasingly interesting for ``conventional'' language implementation, especially as users discover that free isn't free. I.e., explicit memory management can be costly too.
We view GC as part of an allocation service provided by the runtime environment to the user program, usually called the mutator. When the mutator needs heap space, it calls an allocation routine, which in turn performs garbage collection activities if needed.
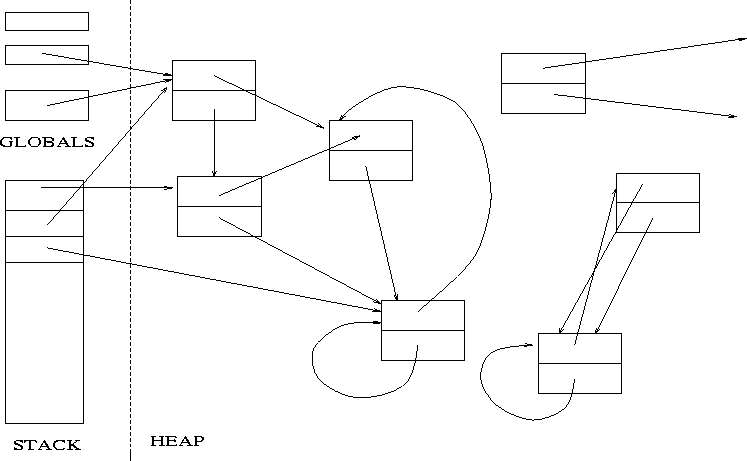
Simple Heap Model
For simplicity, consider a heap containing ``cons'' cells.
Heap consists of two-word cells and each element of a cell is a pointer to another cell. (We'll deal with distinguishing pointers from non-pointers later.)
There may also be pointers into the heap from the stack and global variables; these constitute the root set.
At any given moment, the system's live data are the heap cells that can be reached by some series of pointer traversals starting from a member of the root set.
Garbage is the heap memory containing non-live cells. (Note that this is a slightly conservative definition.) Reference Counting
The most straightforward way to recognize garbage and make its space reusable for new cells is to use reference counts.
We augment each heap cell with a count field that records the total number of pointers in the system that point to the cell. Each time we create or copy a pointer to the cell, we increment the count; each time we destroy a pointer, we decrement the count.
If the reference count ever goes to 0, we can reuse the cell by placing it on a free list.

When allocating a new cell, we first try the free list (before extending the heap).
Pros:
Conceptually simple;
Immediate reclamation of storage
Cons:
Extra space;
Extra time (every pointer assignment has to change/check count)
Can't collect ``cyclic garbage''
Mark and Sweep
There's no real need to remove garbage as long as unused memory is available. So GC is typically deferred until the allocator fails due to lack of memory. The collector then takes control of the processor, performs a collection--hopefully freeing enough memory to satisfy the allocation request--and returns control to the mutator. This approach is known generically as ``stop and collect.''
There are several options for the collection algorithm. Perhaps the simplest is called mark and sweep, which operates in two phases:
![]() First, mark each live data cell by tracing all pointers
starting with the root set.
First, mark each live data cell by tracing all pointers
starting with the root set.
![]() Then, sweep all unmarked cells onto the free list
(also unmarking the marked cells).
Then, sweep all unmarked cells onto the free list
(also unmarking the marked cells).
![\begin{code}\cdmath
struct cell \{
int mark:1;
struct cell *c[2];\}
\par struc...
...
\par struct cell heap[HEAPSIZE];
\par struct cell *roots[ROOTS];
\par\end{code}](img17.gif)
![\begin{code}\cdmath
/* Initially all cells are on free list.
Use c[0] to link m...
...ore room */
die();
\};
a = free;
free = free->c[0];
return a;
\}\end{code}](img18.gif)
![\begin{code}\cdmath
void gc() \{
for (i = 0; i < ROOTS; i++)
mark(roots[i]);
...
...].mark = 0;
else \{
heap[i].c[0] = free;
free = &(heap[i]);
\}
\}
\end{code}](img19.gif)
Here mark traverses the live data graph in depth-first order,
and potentially uses lots of stack! A standard trick called
pointer reversal can be used to avoid needing extra space during
the traversal.
Copying Collection
Mark and sweep has several problems:
![]() It does work proportional to the size of the entire heap.
It does work proportional to the size of the entire heap.
![]() It leaves memory fragmented.
It leaves memory fragmented.
![]() It doesn't cope well with non-uniform cell sizes.
It doesn't cope well with non-uniform cell sizes.
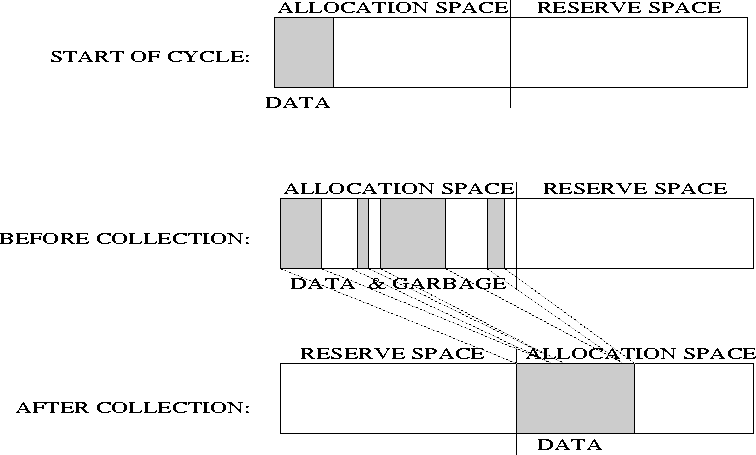
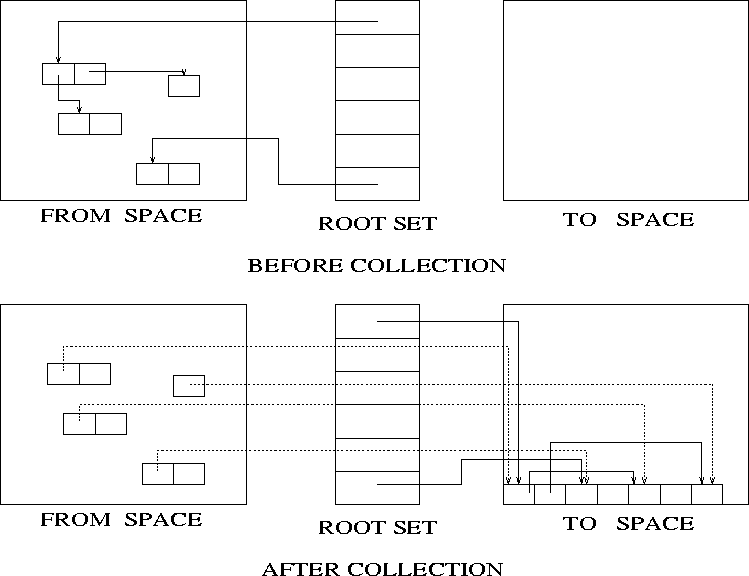
An alternative that solves these problems is copying collection. The idea is to divide the available heap into 2 semi-spaces. Initially, the allocator uses just one space; when it fills up, the collector copies the live data (only) into the other space, and reverses the role of the spaces.
Copying collection must fix up all pointers to copied data. To do this, it leaves a forwarding pointer in the ``from'' space after the copy is made.
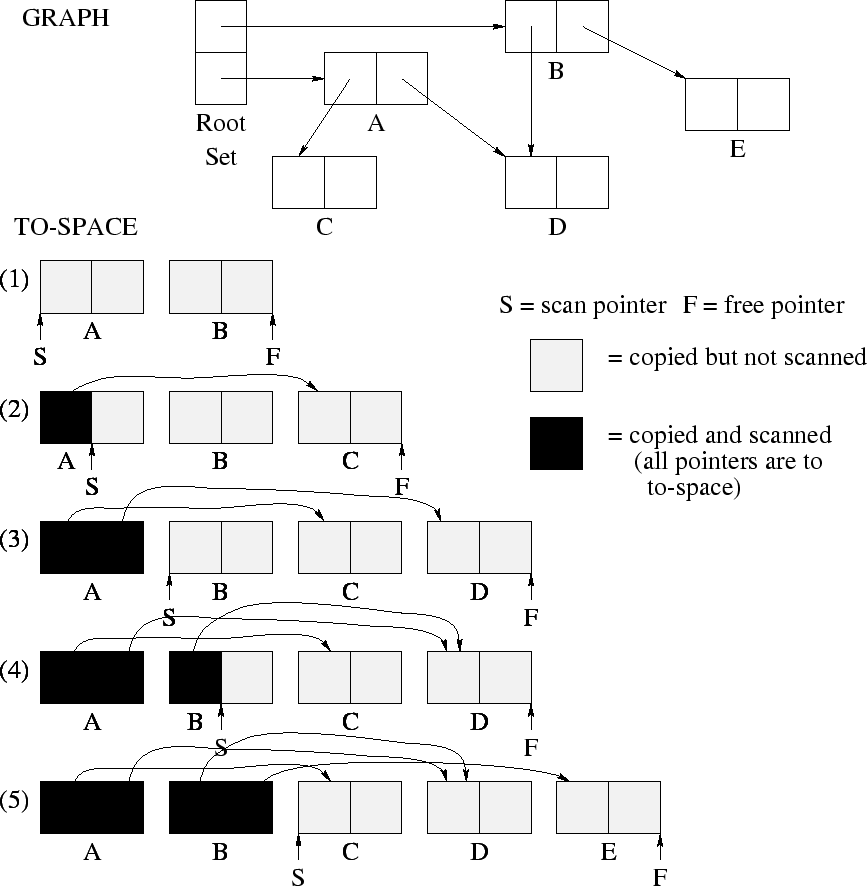
A copying collector typically traverses the live data graph breadth first, using ``to'' space itself as the search ``queue.''
Copying compacts live data, which improves locality and may be good for virtual memory and caches.
Copying Collection Details
![\begin{code}\cdmath
struct cell \{
struct cell *c[2];
\}
\par struct cell space...
... if (free == end) /* still no room */
die();
\};
return free++;
\}\end{code}](img23.gif)
![\begin{code}\cdmath
gc() \{
int i;
struct cell *scan = &(space[to\_space][0]);...
...*free = *p;
p->c[0] = free++;
return p->c[0];
\}
else return p;
\}\end{code}](img24.gif)
Comparison
Copying collector does work proportional to amount of live data. Asymptotically, this means it does less work than mark and sweep. Let
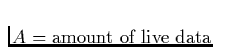

After the collection, there is M-A space left for allocation before the next collection. We can calculate the amortized cost per allocated byte as follows:
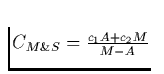 for some c1,c2
for some c1,c2
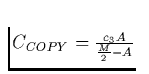 for some c3
for some c3
As
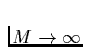 ,
,
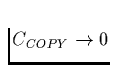 ,
while
,
while
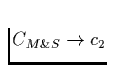 .
.
Of course, real memories aren't infinite, so the values of c1,c2,c3matter, espeically if a significant percentage of data is live at collection (since generally c3 > c1). Further Issues
![]() Distinguishing pointers from integers.
Distinguishing pointers from integers.
![]() Handling records of variable size.
Handling records of variable size.
![]() Finding the root set.
Finding the root set.
![]() Avoiding repeated copying of permanently live data.
Avoiding repeated copying of permanently live data.
![]() Avoiding nasty pauses during collection.
Avoiding nasty pauses during collection.
These concerns lead to the study of three important varieties of collectors:
![]() Conservative collectors.
Conservative collectors.
![]() Generational collectors.
Generational collectors.
![]() Incremental collectors.
Incremental collectors.