

Methods for Designing Cellular
Automata with ``Interesting''
Behavior
H.A. Gutowitz and C.G. Langton
Cellular automata are dynamical systems in which space, time, and the states
of the system are discrete. Each cell in a regular lattice changes its state
with time according to a rule which is local and deterministic. All cells on the
lattice obey the same rule. Given a randomly-chosen cellular automaton rule, how
do we expect it will behave? The following is an informal account of some
attempts to answer this question quantitatively.
Wolfram (1983) addressed the issue by dividing cellular automata into four
broad, largely qualitative classes: I) very dull (all configurations
map to a homogeneous state), II) dull (all configurations map eventually to
simple separated periodic structures), III) interesting (produce chaotic
patterns, large-time prediction of behavior is impossible, though precise
statistical statements may be made), IV) very interesting (produce
propagating structures, sometimes soliton-like, may perform useful computations,
have behavior which is provably undecideable etc). He indicated that most
cellular automata were of the class III variety.
More recently, we have been working to form some more quantitative
expectations about what the space of cellular automata contains. Coming from two
rather different perspectives, and using rather different techniques, we have
arrived at remarkably similar conclusions: most cellular automata are indeed in
class III, in the sense that they produce chaotic-looking patterns, but they are
hardly ``interesting''. All patterns of cell states over a finite region may
occur at large-time, and what's more, occur with probabilty depending only on
the size of the region. That is, phase space is uniformly filled, there is no
order within chaos, there is simply a random gas of cell states. Even if we
input structure into these rules in terms of initial conditions, this structure
is destroyed.
We will call such cellular automata dull, but dull for a different reason
than the dullness of classes I and II. Not all cellular automata are dull, but
most are, and the fraction of rules which are dull rapidly approaches 1 as the
size of the neighborhood or the number of possible cell states is increased.
So, if most cellular automata are dull, what makes for ``interestingness'' in
cellular automata, and what properties do ``interesting'' cellular automata
share?
Cellular automata are interesting when their global behavior is more than the
sum of the behaviors of their individual parts: the cells. Thus, the individual
cells in interesting CA must interact cooperatively in some fashion in support
of the global dynamics. In order to do so, cells must communicate information
between themselves in a meaningfull manner.
Class I, II, and most class III CA's are dull precisely because information
cannot be transmitted between cells in any meaningfull manner. In classes I and
II, information is not transmitted. In most class III CA's, although information
is transmitted, it is not transmitted in a useful form, and in fact the generic
behavior of this class is very similiar to the behavior of lattices where the
values of each site are updated by picking the next state with uniform-random
bias over the state set.
In short, Classes I and II exhibit too much inter-cell dependence for useful
information processing to take place, and most Class III CA's exhibit too little
inter-cell dependence for useful information processing to take place. Too much
or too little dependence between cells sets the stage for dull behavior. The
criterion for interesting cellular automata, then, is to achieve some sort of
tradeoff between too-much and too-little inter-cell dependence.
Although it is true that the generic cellular automaton picked at random is
dull, methods exist for generating CA rules that are quite likely to support
interesting behavior.
One of these methods (Langton 1988) involves parameterizing the space of CA
rules in such a way that interesting behavior can be ``tuned in'' by twisting
the parameter knob. The parameter used is a simple measure of the distribution
of state transitions in the transition rule. For CA with a symmetric quiescent
condition (homogeneous neighborhoods do not change), we arbitrarily pick one of
the states and call it the reference state 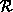 . If we let
P() be the
percentage of transitions to state in the rule
table, then we define the parameter lambda as:
. If we let
P() be the
percentage of transitions to state in the rule
table, then we define the parameter lambda as: 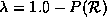 . We now use
. We now use
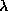 to
generate random CA transition rules as follows. Pick a value for and divide the
remaining probability of
to
generate random CA transition rules as follows. Pick a value for and divide the
remaining probability of 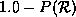 equally among the remaining states. Walk through the rule table
filling in the transitions using these probabilities. Thus, for
equally among the remaining states. Walk through the rule table
filling in the transitions using these probabilities. Thus, for 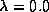 , all
the transitions save the non- homogeneous
neighborhoods will be to state , for
, all
the transitions save the non- homogeneous
neighborhoods will be to state , for 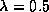 , half of the
transitions will be to state and the
remaining transitions will be equally distributed among the other states, and
for
, half of the
transitions will be to state and the
remaining transitions will be equally distributed among the other states, and
for 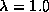 ,
none of the transitions will be to , and the other
states will be represented equally in the transition table. Twisting the knob
generating a series of transition rules and studying the behavior of CA's run
under the rule-tables so-generated is a simple way to search for structure and
interesting regions in CA rule-space.
,
none of the transitions will be to , and the other
states will be represented equally in the transition table. Twisting the knob
generating a series of transition rules and studying the behavior of CA's run
under the rule-tables so-generated is a simple way to search for structure and
interesting regions in CA rule-space.
The measure we use to distinguish interesting from dull CA's is the
mutual information between two cells, 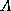 and
and 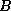 , separated in
time and/or space. The mutual information is defined as the sum of the entropy
of the individual cells minus the entropy of the joint process:
, separated in
time and/or space. The mutual information is defined as the sum of the entropy
of the individual cells minus the entropy of the joint process:
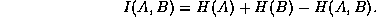
The mutual information is bounded above by the entropy of the individual
cells. In the case of independent behavior of and , 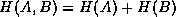 and so
and so 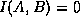 . In the case
where and
are
totally dependent,
. In the case
where and
are
totally dependent, 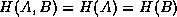 so
so 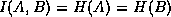 . Mutual information thus gives a useful handle on the ebb and flow
of information within a CA.
. Mutual information thus gives a useful handle on the ebb and flow
of information within a CA.
Figure 1 shows the raw data for 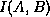 vs
for
approximately
vs
for
approximately 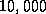 randomly generated, 2D cellular automata allowing 8 states per
cell. Here, cell is just cell one time step
later. The most obvious features are 1) the bimodal distribution and the
approximate range of
randomly generated, 2D cellular automata allowing 8 states per
cell. Here, cell is just cell one time step
later. The most obvious features are 1) the bimodal distribution and the
approximate range of 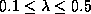 where the highest values for are found, 2)
the sharp convergence toward the extended tail, and 3) the non-zero value of
for high
values of . Taking these in order, the bimodal distribution reflects the
different classes of automata mentioned above. Classes I and II are found
primarily in the lower cluster, Class III is found primarily in the extended
tail, and Class 4, the interesting class, is found primarily in the humped part
of the upper cluster, i.e., associated with the higher values of , as one would
expect if interesting behavior depends on the meaningful transmission of
information. The sharp convergence toward the extended tail reflects the
qualitative change in behavior between interesting Class IV behavior to the left
and dull class III behavior to the right. The tightly converged, non-zero value
for at
the end of the extended tail is characteristic for Class III CA's and might be
referred to as the ``cosmic background mutual information'' in the array, due to
the fact that all of the cells in the array are obeying the same transition
function. It is what is measured even between cells that are separated by large
distances in space under chaotic rules. Subtracting out this background
correlation yields a value very close to zero for most Class III CA's,
consistent with the interpretation that even neighboring cells are effectively
behaving independently.
where the highest values for are found, 2)
the sharp convergence toward the extended tail, and 3) the non-zero value of
for high
values of . Taking these in order, the bimodal distribution reflects the
different classes of automata mentioned above. Classes I and II are found
primarily in the lower cluster, Class III is found primarily in the extended
tail, and Class 4, the interesting class, is found primarily in the humped part
of the upper cluster, i.e., associated with the higher values of , as one would
expect if interesting behavior depends on the meaningful transmission of
information. The sharp convergence toward the extended tail reflects the
qualitative change in behavior between interesting Class IV behavior to the left
and dull class III behavior to the right. The tightly converged, non-zero value
for at
the end of the extended tail is characteristic for Class III CA's and might be
referred to as the ``cosmic background mutual information'' in the array, due to
the fact that all of the cells in the array are obeying the same transition
function. It is what is measured even between cells that are separated by large
distances in space under chaotic rules. Subtracting out this background
correlation yields a value very close to zero for most Class III CA's,
consistent with the interpretation that even neighboring cells are effectively
behaving independently.
Another method for cellular automaton engineering (Gutowitz, 1988) involves
the mean field theory for cellular automata, and a generalization of the mean
field theory, called local structure theory (Gutowitz et al. 1987). Cellular
automata are replaced by real-valued recursion equations. These equations are
then examined for desired behavior. Finally, a (non-unique) inverse map is
applied to find cellular automata which correspond to the selected recursion
equations.
The mean field theory is derived from the assumption that no correlations
between cell states are generated in the course of cellular automaton evolution.
This assumption leads one to associate a simple system of polynomial recursion
equations with a cellular automaton. This system of equations gives the
probability of each cell state at a given time in terms of the probability of
each cell state at the previous time. The roots of equations provide estimates
for the large-time probability of each cell state. For present purposes, the
fundamental observation is that many distinct cellular automata may lead to the
same mean field system of equations. Hence the roots of a given mean field
theory expression are estimates for the large-time behavior of all
cellular automata which give rise to the expression. By varing parameters in the
mean field theory, the behavior of a vast number of cellular automata may be
explored in short order. Regions of parameter space which represent rare,
interesting, behavior may be located. There are at least two technical
challenges: 1) to work backward from a mean field theory expression to the set
of rules which give rise to that expression, and 2) to verify that rules which
have the same mean field expressions in fact have similar properties.
The method which yields all cellular automata with a given mean field
expression relies on writing these equations as a sum of probabilities of blocks
of a given type, weighted by an integer-valued coefficient. The type of
block depends only on how many cells in each of the possible states it contains.
Let 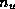 be
the number of blocks of a given type
be
the number of blocks of a given type  . The
coefficient,
. The
coefficient, 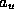 , indexes the number of blocks of this type which yield a
particular value when the CA rule is applied. To find all the rules which have
mean field expressions with a particular set of coefficients, one must list all
, indexes the number of blocks of this type which yield a
particular value when the CA rule is applied. To find all the rules which have
mean field expressions with a particular set of coefficients, one must list all
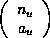 ways of
achieving the values with subsets of blocks. Each
way of doing this corresponds to a different cellular automaton rule. The total
number of rules with a given expression is the product over all types of
ways of
achieving the values with subsets of blocks. Each
way of doing this corresponds to a different cellular automaton rule. The total
number of rules with a given expression is the product over all types of 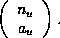 Having found
all cellular automata with a given mean field expression, we can empirically
test if they have similar behavior. A summary of a large number of Monte Carlo
experiments in this direction is the following: cellular automata which give
rise to a mean field expression which predicts dull or interesting behavior tend
to be dull or interesting respectively. Still, the mean field theory fails too
often to permit precision engineering.
Having found
all cellular automata with a given mean field expression, we can empirically
test if they have similar behavior. A summary of a large number of Monte Carlo
experiments in this direction is the following: cellular automata which give
rise to a mean field expression which predicts dull or interesting behavior tend
to be dull or interesting respectively. Still, the mean field theory fails too
often to permit precision engineering.
Improvement of the mean field theory requires that the assumption that no
correlations between cell states are generated by cellular automata be relaxed.
A sequence of generalizations (Gutowitz et al. 1987) of the mean field theory
has been devised in which correlations are represented in terms of the
probability of blocks of length 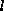 . Whereas the
mean field theory gave the probability of each cell state at a given in terms of
the probability of the cell states at the previous time, the -th order
generalization gives the probabiltiy of each -block at a
given time in terms of the probability of the -blocks at the
previous time. The fixed points of these equations again yield estimates of the
large-time behavior of the cellular automata which gave rise to them. As in the
case of mean field theory, it is possible (though involved) to construct an
inverse map from a high-order theory to the corresponding set of CA. The
high-order theories have several advantages, among them: 1) they yield more
accurate estimates of limiting behavior of individual cellular automata, 2) the
set of cellular automata with a given high-order expression tend to be more
similar to each other than those which mearly share the same mean field
expression, 3) the number of rules which share a high-order expression is
typically smaller than the number of rules which share a given low-order
expression. In short, the higher the order of theory, the more finely and
accurately is the space of cellular automata broken into behavioral classes of
rules. By adjusting the parameters of a high-order theory, it is possible not
only to locate interesting rules, but interesting rules with precisely the
properties desired.
. Whereas the
mean field theory gave the probability of each cell state at a given in terms of
the probability of the cell states at the previous time, the -th order
generalization gives the probabiltiy of each -block at a
given time in terms of the probability of the -blocks at the
previous time. The fixed points of these equations again yield estimates of the
large-time behavior of the cellular automata which gave rise to them. As in the
case of mean field theory, it is possible (though involved) to construct an
inverse map from a high-order theory to the corresponding set of CA. The
high-order theories have several advantages, among them: 1) they yield more
accurate estimates of limiting behavior of individual cellular automata, 2) the
set of cellular automata with a given high-order expression tend to be more
similar to each other than those which mearly share the same mean field
expression, 3) the number of rules which share a high-order expression is
typically smaller than the number of rules which share a given low-order
expression. In short, the higher the order of theory, the more finely and
accurately is the space of cellular automata broken into behavioral classes of
rules. By adjusting the parameters of a high-order theory, it is possible not
only to locate interesting rules, but interesting rules with precisely the
properties desired.
Clearly, applications abound. An application currently being pursued is the
design of cellular automata whose natural measure corresponds to the scaling
function of given smooth dynamical systems, e.g. golden mean rotation or
period-doubling.
We can summarize our results with an analogy which may be taken quite
literally. The dullest forms of matter are regular crystals at one end, and
ideal gases at the other. In the first case, each atom of the crystal has
perfect information about every other atom. In the second case, each molecule of
the gas has no information about any other molecule. A small fraction of
cellular automata are like crystals, and the bulk of cellular automata are like
ideal gases. The analytical methods used to study crystals are applicable to
this first set of automata, and the analytical methods used to study gases are
applicable to the second set of automata. In particular, the mean field theory
is an excellent approximation for many cellular automata.
Between these extremes lie the liquids on one hand, and the interesting
cellular automata on the other. Here correlations between entites exist, but
tend to decay with distance at a finite, but non-zero rate. Entities cooperate
to form macroscopic patterns, often shifting and unstable. The assumptions of
the mean field theory are no longer valid. Analysis must take the sharing of
information between entities into account explicitly. Both methods described
here for the design of cellular automata rely on a breakdown of the
no-mutual-information assumption to signal the presence of an interesting
cellular automaton.
References
H.A. Gutowitz Cellular Automata which Possess a Natural
Measure,
In preparation. (1988).
H.A. Gutowitz, J.D. Victor, B.W. Knight Local Structure Theory
for
Cellular Automata, Physica D 29:18. (1987).
C.G. Langton Structure in Cellular Automaton Rule Space,
In
preparation (1988).
S. Wolfram Statistical Mechanics of Cellular Automata,
Rev. Mod.
Phys. 55:601 (1983).
Wed Nov 9 19:38:15 GMT 1994