Project 1
Spring 2010
CS 410/584 Algorithm Design & Analysis
Overview: Railway
Networks
Consider a railway network consisting of two kinds of nodes: endpoints and switches. These nodes are connected by edges that are called segments. In the figure below, a, c and d are endpoints, b is a switch, and s1, s2 and s3 are segments. An endpoint always has exactly one segment connected to it. A switch always connects three segments. One segment is designated as the trunk for the switch; the other two segments are branches. In the figure, we draw an arc between the two branches: for switch b, segment s1 is the trunk and segments s2 and s3 are the branches.
Trains move from segment to segment through switches, with the restriction that the movement must always be from trunk to branch or branch to trunk, but never directly from branch to branch. A train has a direction on a segment. If a train is facing towards a switch b before passing through, then it will be facing away from b after passing through, and vice versa.
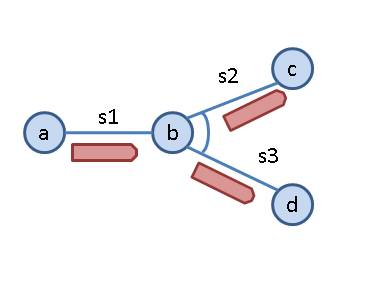
A route through the railway network is a series of segments s1 s2 … sk such that for each pair si si+1there is a switch b such that si is a branch for b and si+1 a trunk, or si is a trunk for b and si+1 is a branch. A switchback on a route is a triple of consecutive segments s2, s1, s3 such that there a switch b where s1 is the trunk and s2 and s3 are the branches. (We would also consider it a switchback if the route contains something like s2, s1, s5, s6, s5, s1, s3. We are trying to account for the number of times the train has to reverse direction through a switch to get between its branches.)
This assignment can be done in pairs, in any programming language you wish, but each person must turn in his or her own write-up, described below. The assignment is due at the beginning of class on Thursday, 5 May.
Interesting Links
Original article by Brian Hayes that gave me the idea for the assignment: Trains of Thought
Wikipedia article on Railroad switch.
YouTube video of simulated railway network.
Stability
of Timetables and Train Routings through Station Regions: See
Chapter 3 of this doctoral dissertation for a definition of double vertex networks, which are a way
to represent railway networks that takes into account the limitations of
switches.
Algorithms
You should implement algorithms for the following two problems. You can use whatever programming language you wish.
Problem 1: Given segments ss and se, find a route ss s1 s2 … sk se with the fewest switchbacks.
Problem 2: Given a train on segment s, find the route s s1 s2 … sk s with the fewest segments that brings the train back to the starting segment, but oriented in the opposite direction (or report that no such route exists).
Both algorithms should keep a count of “basic steps”. What your basic step is will depend on you algorithm, but it should be something that is proportional to the total work the algorithm does, such as number of visits to nodes and segments.
Each algorithm should output its input segment(s), the minimum route along with the count of switchbacks or segments, and the number of basic steps required.
Note: You might want to model each segment as being directed, so as to have something relative to which you can express a train’s direction.
Data and Test Runs
A dataset for a railway network will be given as an incidence list, with one line for each endpoint and swtich.
- An endpoint n with segment s is represented n:s. (the period is part of the representation)
- A switch m with trunk s1 and branches s2 and s3 is represented m:s1;s2,s3
Both nodes and segments are represented by integers.
Here are two sets of sample data.
Sample Data #1: sample1.txt. This network does not allow train reversals.
Sample Data #2: sample2.txt. This network permits reversals, and also exhibits some unusual cases that are allowed (parallel segments and a segment connecting twice to the same switch).
Test data: testdata.txt
You will need to use this dataset to do 5 runs of each algorithm, each with a different input.
Write Up
Each person in the group must turn in his or her own write-up, which is expected to be about 3 pages plus test output. The write up will have three parts for each algorithm.
- Descriptions of the algorithms you implemented, as pseudo-code with accompanying commentary. Be sure to discuss any major data structures you use.
- An explanation of what the basic step is you are counting for each of the algorithms.
- A discussion of the correctness and time complexity of each algorithm.
You do not need to turn in a listing of your program. Both people can turn in the same test ouput.
Grading Scheme
There are 80 points possible, 40 for each program, divided as follows.
A. (10 points) Test runs
B. (15 points) Description of approach and pseudocode
C. (5 points) Definition and reporting of basic steps
D. (10 points) Analysis of correctness and complexity