CS163 Data Structures
Week #6
Notes
Sorting strategies
• Chapter 9: Sorting (page 405):
Introduction and notation, selection sort, bubble sort
• Also, demonstrate the insertion sort
Sorting and an
Introduction to Trees
• Sorting: Quick Sort
• Also, demonstrate the merge sort
• How to measure efficiency
• Comparison of algorithms
• Chapter 10: Trees
Sorting
• Sorting is the
process that organizes collections of data into either ascending or descending
order.
• Many of the
applications you will deal with will require sorting; it is easier to
understand data if it is organized numerically or alphabetically in order. Just
imagine how difficult it would be to select which classes you are to take next
term if the PSU catalogue wasn't sorted into department categories..and within
that sorted by the class number! It would take forever to find which classes
are available and which ones to take!
• In addition, as we
found with the binary search, our data needs to be sorted to be able use more
efficient methods of searching.
• Just like with
searching, there are two categories of sorting algorithms. Internal sorting requires that all of your data fit into memory
(either an array or a linked list). External
sorting is used when your data can't fit into memory all at once (maybe you
have a very large database), and so sorting is done using disk files.
• Just like with
searching, when we want to sort we need to pick from our data record the key to
sort on (called the sort key). For
example, if our records contain information about people, we might want to sort
their names, id #s, or zip codes. Given a sorting algorithm, your entire table
of information will be sorted based on only one field (the sort key).
• Notation we will be
using throughout our discussion of sorting:
L -- is the list of items to be sorted
key - is each item's key in the list
L might be an array -- containing a
contiguous list of information. In this case, every element of the array would
be a record and the index of the array will range from 0 to max-count-1.
Therefore L[0].key would be the first key in the list.
Or, L might be a linked list -- containing
a series of connected nodes where each node has an item and a next pointer.
Therefore the first key in the list would be L->key.
• The efficiency of
our algorithms is dependent on the number of comparisons we have to make with
our keys. In addition, we will learn that sorting will also depend on how
frequently we must move items around.
Insertion
Sort
• Think about a deck
of cards for a moment. If you are dealt a hand of cards, imagine arranging the
cards. One way to put your cards in order is to pick one card at a time and
insert it into the proper position. The insertion sort acts just this way!
• The insertion sort
divides the data into a sorted and unsorted region. Initially, the entire list
is unsorted. Then, at each step, the insertion sort takes the first item of the
unsorted region and places it into its correct position in the sorted region.
Here is an illustration of the insertion
sort -- starting with 5 integers:
29 10 14 37 13 The
underlined portion is the sorted region
29 10 14 37 13
10 29 14 37 13
10 14 29 37 13
10 14 29 37 13
10 13 14 29 37
• Notice, the insertion sort uses
the idea of keeping the first part of the list in correct order, once you've
examined it. Now think about the first item in the list. Using this approach,
it is always considered to be in order! So, for 5 items in our list, we only
need to perform the search on only 4 numbers to find out where to properly
insert them.
• Here is an array implementation
of our list. Notice that to insert into the sorted region requires that we
shift the array elements to make room for the insertion.
void
insertionsort(list L [], int n) {
int
unsorted; //first element of our
unsorted list
int
loc; //index where we want to
insert our data
int
done;
list
item;
for
(unsorted = 1; unsorted < n; unsorted++) {
item
= L[unsorted];
loc
= unsorted;
done
= 0; //false
while
((loc > 0) && !done) {
if
(L[loc-1] > item) {
L[loc]
= L[loc-1]; //shift right
loc--;
}
else
done
= 1; //true
}
L[loc]
= item; //insert items
}
}
• Suggestion: step thru how this
works with our list of 5 numbers...
• On your own, work through the
code for an insertion sort using a linked list implementation.
• Notice that with an insertion
sort, even after most of the items have been sorted, the insertion of a later
item may require that you move MANY of the numbers. We only move 1 position at
a time. Thus, think about a list of numbers organized in reverse order? How
many moves do we need to make?
10 8 7 5 2
8 10 7 5 2 one
comparison; one shift
7 8 10 5 2 one
comparison; two shifts
5 7 8 10 2 one
comparison; three shifts
2 5 7 8 10 one
comparison; four shifts
Just
imagine if each of these data items was really a structure, containing each
student's transcripts or a complete personnel file for each employee. Each
movement would require a large amount of information to be moved and would
require excessive time.
So,
our goal, in these cases, is to place our data in ITS FINAL position when we
move it. Instead of re-moving the same piece of data over and over again. This
is called....selection sort....
Selection
Sort
• Imagine the case where we can
look at all of the data at once...and to sort it...find the largest item and
put it in its correct place. Then, we find the second largest and put it in its
place, etc. If we were to think about cards again, it would be like looking at
our entire hand of cards and ordering them by selecting the largest first and
putting at the end, and then selecting the rest of the cards in order of size.
• This is called a selection sort.
It means that to sort a list, we first need to search for the largest key.
Because we will want the largest key to be at the last position, we will need
to swap the last item with the largest item.
The
next step will allow us to ignore the last (i.e., largest) item in the list.
This is because we know that it is the largest item...we don't have to look at
it again or move it again!
So,
we can once again search for the largest item...in a list one smaller than
before. When we find it, we swap it with the last item (which is really the
next to the last item in the original list). We continue doing this until there
is only 1 item left.
• Look at our list of 5 numbers
again...and walk thru how this approach works.
29 10 14 37 13 The
underlined portion is ignored
29 10 14 13 37
13 10 14 29 37
13 10 14 29 37
10 13 14 29 37 We
are done!
• The pseudo code to perform this
on an array implementation of our list would be:
void selectionsort(list L [], int n) { //n is the size of the array
int
largest, last, j;
list
temp;
for
(last = n-1; last > 0; last--) {
//find
the largest element
largest
= 0;
for
(j = 1; j <= last; j++)
if
(L[j] > L[largest])
largest
= j;
//swap
the largest element with the last one
temp
= L[largest];
L[largest]
= L[last];
L[last]
= temp;
}
}
• Selection sort doesn't require
as many data moves as Insertion Sort. Therefore, if moving data is expensive
(i.e., you have large structures), a selection sort would be preferable over an
insertion sort.
Shell Sort
• The selection sort
moves items very efficiently but does many redundant comparisons. And, the
insertion sort, in the best case can do only a few comparisons -- but
inefficiently moves items only one place at a time.
• The shell sort is
similar to the insertion sort, except it solves the problem of moving the items
only one step at a time. The idea with the shell sort is to compare keys that
are farther apart, and then resort a number of times, until you finally do an
insertion sort:
Start with:
29 10 14 37 13 5 3 11 38
To begin with, sort every 4 numbers:
so we will be comparing
29 <-> 13 <-> 38
10
<-> 5
14 <-> 3
37 <-> 11
So, we sort each of these:13
<-> 29 <-> 38
5
<-> 10
3 <-> 14
11 <-> 37
Which gives us a new list of:
13 5 3 11 29 10 14 37 38
The next step is to make another
pass, using a smaller increment...like every 2 numbers:
so we will
be comparing 13 <-> 3 <-> 29 <-> 14 <-> 38
5
<-> 11 <-> 10 <-> 37
so we sort
each of these: 3 <-> 13 <->
14 <-> 29 <-> 38
5
<-> 10 <-> 11 <-> 37
Which gives us a new list of:
3 5 13 10 14 11 29 37 38
The
next step is a regular insertion sort: underline is the sorted region
3 5 13 10 14 11 29 37 38
3 5 13 10 14 11 29 37 38
3 5 13 10 14 11 29 37 38
3 5 10 13 14 11 29 37 38 1 shift
3 5 10 13 14 11 29 37 38
3 5 10 11 13 14 29 37 38 2 shifts
3 5 10 11 13 14 29 37 38
3 5 10 11 13 14 29 37 38
3 5 10 11 13 14 29 37 38
• With the shell sort
you can choose any increment you want. Some, however, work better than others.
A power of 2 is not a good idea. Notice the previous example. Step thru the
last example using 5, 3, and 1 instead. Powers of 2 will compare the same keys on
multiple passes...so pick numbers that are not multiples of each other. It is a
better way of comparing new information each time.
The final increment must always be 1.
Start with:
29 10 14 37 13 5 3 11 38
To begin with, sort every 5 numbers:
so we will be comparing
29 <-> 5 10 <-> 3
14 <-> 11
37 <-> 38
13
We sort each of these:5 <-> 29
3
<-> 10
11 <-> 14
37 <-> 38
Which gives us a new list of:
5 3 11 37 13 29 10 14 38
The
next step is to make another pass, using a smaller increment (eg., 3):
so we will
be comparing 5 <-> 37 <-> 10
3
<-> 13 <-> 14
11 <-> 29 <-> 38
so we sort
each of these: 5 <-> 10 <-> 37
3
<-> 13 <-> 14
11 <-> 29 <-> 38
Which gives us a new list of:
5 3 11 10 13 29 37 14 38
The
next step is a regular insertion sort: underline is the sorted region
5 3 11 10 13 29 37 14 38
3 5 11 10 13 29 37 14 38 1 shift
3 5 11 10 13 29 37 14 38
3 5 10 11 13 29 37 14 38 1 shift
3 5 10 11 13 29 37 14 38
3 5 10 11 13 29 37 14 38
3 5 10 11 13 29 37 14 38
3 5 10 11 13 14 29 37 38 2
shifts
Bubble
sort -- also called exchange sort
• Many of you should already be
familiar with the bubble sort. It is used here as an example, but it is not a
particular good algorithm!
• The bubble sort simply compares
adjacent elements and exchanges them if they are out of order. To do this, you
need to make several passes over the data. During the first pass, you compare
the first two elements in the list. If they are out of order, you exchange
them. Then you compare the next pair of elements (positions 2 and 3). If they
are out of order, you exchange them. This algorithm continues comparing and
exchanging pairs of elements until you reach the end of the list.
• Notice that the list is not
sorted after this first pass. We have just "bubbled" the largest
element up to its proper position at the end of the list! During the second
pass, you do the exact same thing....but excluding the largest (last) element
in the array since it should already be in sorted order. After the second pass,
the second largest element in the array will be in its proper position (next to
the last position).
An
example: PASS #1
29 10 14 37 13 The
underlined portion is compared
10 29 14 37 13
10 14 29 37 13
10 14 29 37 13
10 14 29 13 37 the largest has bubbled to the end
PASS
#2
10 14 29 13 37 the bold portion is ignored
10 14 29 13 37
10 14 29 13 37
10 14 13 29 37
PASS
#3
10 14 13 29 37
10 14 13 29 37
10 13 14 29 37
In
the best case, when the data is already sorted, only 1 pass is needed and only
N-1 comparisons are made (with no exchanges).
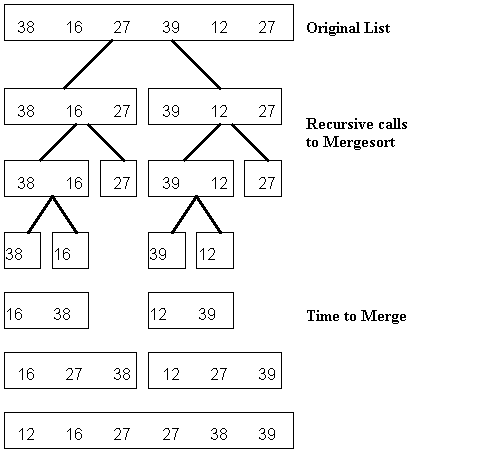
Mergesort
• The mergesort is
considered to be a divide and conquer sorting algorithm (as is the quicksort ).
The mergesort is a recursive approach which is very efficient. The mergesort
can work on arrays, linked lists, or even external files.
• The mergesort is a
recursive sorting algorithm that always gives the same performance regardless
of the initial order of the data. For example, you might divide an array in
half - sort each half - then merge the sorted halves into 1 data structure. To
merge, you compare 1 element in 1 half of the list to an element in the other
half, moving the smaller item into the new data structure.
• The sorting method
for each half is done by a recursive call to merge sort. That is why this is a
divide and conquer method.
• Thus, the pseudo
code is:
Mergesort(list,starting place, ending
place)
if the starting place is less than the
ending place then
middle place = (starting + ending)
div 2
mergesort(list, starting place,
middle place)
mergesort(list,middle place+1,
ending place)
merge the 2 halves of the
list(list,starting,middle,ending)
else -- return!
• Believe it or not -
this algorithm really does sort!
• If we implemented
this approach using arrays ---
If the total number of items in your list
is m...then
for each merge we must do m-1 comparisons. For example, if there are 6 items we must do
five comparisons. In addition, there are m moves from the original location
to some temporary location (and back).
Even though this seems like alot, you will
see that this is actually faster than either the selection sort or the
insertion sort.
Although the mergesort is extremely
efficient with respect to time, it does require that an equal
"temporary" or "auxiliary" array be used which is the same
size as the original array. If temporary arrays are not used...this approach
ends up being no better than any of the others we have discussed - and becomes
very complicated!
• If we implement the
mergesort using linked lists, we do not need to be concerned with the amount of
time needed to move data items. Instead, we just need to concentrate on the
number of comparisons. When lists get very long, the number of comparisons is far less with the mergesort than it is
with the insertion sort. Problems requiring 1/2 hour of computer time using the
insertion sort will probably require no more than a minute using the mergesort.
Quicksort
• The quicksort is also considered
to be a divide and conquer sorting algorithm. The quicksort partitions a list
of data items that are less than a pivot point and those that are greater than
or equal to the pivot point.
• You could think of this as
recursive steps:
step
1 - choose a pivot point in the list of items
step
2 - partition the elements around the pivot point.
This
generates two smaller sorting problems, sorting the left section of the list
and the right section (excluding the pivot point...as it is already in the
correct sorted place). Once each of the left and right smaller lists are sorted
in the same way, the entire list will be sorted (this terminates the recursive
algorithm).
• The pseudo code for a quicksort
might look like:
Quicksort(List,
starting point, ending point)
if
(starting point < ending point) then
choose
a pivot point in the List
go
thru the list and place the smaller items to the left and the
larger
items to the right of the pivot (called partitioning)
quicksort
(List, starting point, pivot point -1)
quicksort(List,
pivot point +1, ending point)
else
we are done!
• Notice that partitioning the
list is probably the most difficult part of the algorithm. It must arrange the
elements in two regions: those greater than the pivot and those less. The first
question which might come to mind is which pivot to use? If the elements are
arranged randomly, you can chose a pivot randomly. For example, choose the
first item as your pivot.
Look
at an example of the first partition of a list of numbers when the pivot is the
first element:
27 38 12 39 27 16
pivot
27 38 12 39 27 16 1st comparison; 38 stays in the right
27 12 |
38 39 27 16 2nd comparison; 12 goes to the left
27 12 |
38 39 27 16 3rd comparison; 39 stays in the right
27 12 |
38 39 27 16 4th comparison; 27 stays in the right
27 12 16 |
38 39 27 5th
comparison; 16 goes to the left
Lastly,
place the pivot point between the left and right lists:
12 16 |
27 | 38 39 27 This
is the first "partition"
• We are not required to choose
the first item in the list as the pivot
point. We can choose any item we want and swap it with the first before
beginning the sequence of partitions. In fact, the first item is usually not a
good choice...many times the first item in a list is already sorted. That would
mean that there would be no items in the left partition! Therefore, it might be
better to chose a pivot from the center of the list, hoping that it will divide
the list approximately in two. If you are sorting a list that is almost in
sorted order...this would require less data movement!
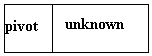
• Taking a closer look at our
example, we see that we really have used another region: called the unknown
region of our list of data. These are the numbers, to the right of the pivot
point that have not been compared yet to the pivot (and are not underlined in
our example). We need to keep track of
where this "unknown" region begins. We call this the
"unknown" region because the relationship between the items in this
part of the list and the pivot point is simply unknown!

• With an array implementation of
the quick sort, first initialize:
pivot
= the starting point
first
unknown = starting point + 1
Which
looks like:
• At each step in the partition
function, we need to examine one element in the unknown region, determine how
it relates to the pivot point, and place it in one of the two regions (< or
=>). Thus, the size of the unknown region decreases by one at each step. The
function terminates when the size of the unknown region reaches zero (i.e.,
when the first unknown index = the ending point).
Look
at the pseudo code for partitioning
using an array implementation:
void
partition (list L [], int starting, int
ending, int & pivot_point) {
list
pivot_value;
int
last_left, first_unknown;
pivot_value
= L[starting];
last_left
= starting;
first_unknown
= starting;
while
(first_unknown <= ending) {
//
determine the relationship with the pivot
if
(L[first_unknown] < pivot_value) {
//
move the first unknown value into the left list
Swap
list[first_unknown] with L[last_left+1];
last_left++;
}
//
"move" the first unknown value into the right list
first_unknown++;
}
//now
we are ready to place the pivot value in the proper position
Swap
List[starting] with L[last_left]
pivot_point
= last_left
}
• Notice that quicksort actually
alters the array itself...not a temporary array.
• Quicksort and mergesort are
really very similar. Quicksort does work before its recursive calls...mergesort
does work after its recursive calls.
• Quicksort has the form:
Prepare
the array for recursive calls
quicksort
(first region)
quicksort
(second region)
• Whereas, Mergesort has the form:
Mergesort(left
half of the list)
Mergesort(right
half of the list)
Tidy
up
• As we've noted, the major effort
with the Quicksort is to partition the data. The worst case with this method is
when one of the regions (left or right) remains empty (i.e., the pivot value
was the largest or smallest of the unknown region). This means that one of the
regions will only decrease in size by only 1 number (the pivot) for each
recursive call to Quicksort.
Also,
notice what would happen if our array is already sorted in ascending order? If
we pick a pivot value as the first value, for each recursive call we only
decrease the size by 1 -- and do SIZE-1 comparisons. Therefore, we will have
many unnecessary comparisons.
The
good news is that if the list is already sorted in ascending order and the
pivot is the smallest #, then we actually do not perform any moves. But, if the
list is sorted in descending order and the pivot is the largest, there will not
only be a large number of un-necessary comparisons but also the same number of
moves.
On
average, quicksort runs much faster than the insertion sort on large arrays. In
the worst case, quicksort will require roughly the same amount of time as the
insertion sort. If the data is in a random order, the quicksort performs at
least as well as any known sorting algorithm that involves comparisons.
Therefore, unless the array is already ordered -- the quicksort is the best
bet!
Mergesort, on the other hand, runs somewhere between
the Quicksort's best and worst case (insertion sort). Sometimes quicksort is
faster; sometimes it is slower! The thing to keep in mind is that the worst
case behavior of the mergesort is about the same as the quicksort's average
case. Usually the quicksort will run faster than the mergesort...but if you are
dealing with already sorted or mostly sorted data, you will get worst case
performance out of the quicksort which will be significantly slower than the
mergesort.
Radix Sort
• Imagine that we are sorting a
hand of cards. This time, you pick up the cards one at a time and arrange them
by rank into 13 possible groups -- in the order 2,3,...10,J,Q,K,A. Combine each
group face down on the table..so that the 2's are on top with the aces on
bottom. Pick up one group at a time and sort them by suit: clubs, diamonds,
hearts, and spades. The result is a totally sorted hand of cards.
• The radix sort uses this idea of
forming groups and then combining them to sort a collection of data. Look at an
example using character strings:
ABC XYZ BWZ AAC RLT JBX RDT KLT AEO TLJ
The
sort begins by organizing the data according to the rightmost (least
significant) letter and placing them into groups:
Group
1: ABC, AAC
Group
2: TLJ
Group
3: AEO
Group
4: RLT, RDT, KLT
Group
5: JBX
Group
6: XYZ, BWZ
Now,
combine the groups into one group like we did the hand of cards. Take the
elements in the first group (in their original order) and follow them by
elements in the second group, etc. Resulting in:
ABC AAC TLJ AEO RLT RDT KLT JBX XYZ BWZ
The
next step is to do this again, using the next letter:
Group
1: AAC
Group
2: ABC, JBX
Group
3: RDT
Group
4: AEO
Group
5: TLJ, RLT, KLT
Group
6: BWZ
Group
7: XYZ
Doing this we must keep the strings within
each group in the same relative order as the previous result. Next, we again
combine these groups into one result:
AAC ABC JBX RDT AEO TLJ RLT KLT BWZ XYZ
Lastly,
we do this again, organizing the data by the first letter:
Group
1: AAC, ABC, AEO
Group
2: BWZ
Group
3: JBX
Group
4: KLT
Group
5: RDT, RLT
Group
6: TLJ
Group
7: XYZ
We
do a final combination of these groups, resulting in:
AAC ABC AEO BWZ JBX KLT RDT RLT TLJ XYZ
The
strings are now in sorted order!
•
When working with strings of varying length, you can treat them as if
the short ones are padded on the right with blanks.
• The pseudo code that describes
this algorithm looks like:
//
Num is the number of strings or numbers to sort
//
Digits is the number of digits in the number or characters in the string
void
RadixSort(List, Num, Digits) {
for
(j=Digits; j <= 1; j--) {
initialize
all groups to being empty
initialize
a counter for each group to be zero
for
(i= 1; i <= Num; i++) {
k
= jth digit of List[i-1]
place
List[i-1] at the end of group k
increase
the kth counter by 1
}
Replace
elements in List with all the elements in group 1, followed
by
all the elements in group 2, etc.
}
}
• Notice just from this pseudo
code that the radix sort requires Num moves each time it forms groups and Num
moves to combine them again into one group. This algorithm performs 2*Num moves
"Digits" times. Notice that there are no comparisons!
• Therefore, at first glimpse,
this method looks rather efficient. However, it does require large amounts of
memory to handle each group if implemented as an array. Therefore, a radix sort
is more appropriate for a linked list than for an array. Also notice that the
worst case and the average case (or even the best case) all will take the same
number of moves.
Comparison of
methods
• Now
that we have become familiar with the selection sort, insertion sort, bubble
sort, shell sort, mergesort, quicksort, and radix sort, it is time to compare
these methods and look at their worst case/average case efficiencies.
• Remember, when comparing the
efficiencies of solutions, we should only look at significant differences and
not overanalyze. In many situations the
primary concern should be simplicity; for example, if you are sorting an array
that contains only a small number of elements (like fewer than 50), a simple
algorithm such as an insertion sort is appropriate. If you are sorting a very
large array, such simple algorithms may be too inefficient. Then, look at
faster algorithms, such as the quicksort if you are confident that the data in
the array is arranged randomly!
Selection
Sort Efficiency
• Selection sort requires both
comparisons and exchanges (i.e., swaps). Start analyzing it by counting the
number of comparisons and exchanges for an array of N elements.
Remember
the selection sort first searches for the largest key and swaps the last item
with the largest item found. Remember that means for the first time around
there would be N-1 comparisons. The
next time around there would be N-2 comparisons (because we can exclude
comparing the previously found largest! Its already in the correct spot!). The
third time around there would be N-3 comparisons. So...the number of
comparisons would be:
(N-1)+(N-2)+...+ 1 = N*(N-1)/2
Next,
think about exchanges. Every time we find the largest...we perform a swap. This
causes 3 data moves (3 assignments). This happens N-1 times! Therefore, a
selection sort of N elements requires 3*(N-1)
moves.
Lastly,
put all of this together:
N*(N-1)/2 + 3*(N-1) which is: N*N/2 - N/2 +
6N/2 - 3
which
is: N*N/2 + 5N/2 - 3
Put
this in perspective of what we learned about with the BIG O method. Remember we
can ignore low-order terms in an
algorithm's growth rate.
And,
you can ignore a constant being
multiplied to a high-order term.
Therefore,
some experts will consider this sorting method to be:
1/2 N*N + O(N)
Other
experts consider this simply to be O(N*N).
Given
this, we can make a couple of interesting observations. The efficiency DOES NOT
depend on the initial arrangement of the data. This is an advantage of the
selection sort. However, O(N*N)
grows very rapidly, so the performance gets worse quickly as the number of
items to sort increases. Also notice that even though there are O(N*N)
comparisons there are only O(N) data moves. Therefore, the selection sort could
be a good choice over other methods when data moves are costly but comparisons
are not. This might be the case when each data item is large (i.e., big
structures with lots of information) but the key is short. Of course, don't
forget that storing data in a linked list allows for very inexpensive data
moves for any algorithm!
Bubble
Sort Efficiency
• The bubble sort also requires
both comparisons and exchanges (i.e., swaps). Remember, the bubble sort simply
compares adjacent elements and exchanges them if they are out of order. To do
this, you need to make several passes over the data.
This
means that the bubble sort requires at most N-1 passes through the array.
During the first pass, there are N-1 comparisons and at most N-1 exchanges. During the second pass,
there are N-2 comparisons and at most N-2 exchanges. Therefore, in the worst
case there are comparisons of:
(N-1)+(N-2)+...+ 1 = N*(N-1)/2
and,
the same number of exchanges... where each exchange requires 3 data moves.
Putting this altogether:
N*(N-1)/2*4 which is: 2N*N - 2*N in the worst case
This
can be summarized as an O(N*N) algorithm
in the worst case. We should keep in mind that this means as our list grows
larger the performance will be dramatically reduced. In addition, unlike the
selection sort, in the worst case we have not only O(N*N) comparisons but also O(N*N) data moves.
But,
think about the best case for a moment. The best case occurs when the original
data is already sorted. In this case, we only need to make 1 pass through the
data and make only N-1 comparisons and NO exchanges. So, in the best case, the bubble sort O(N).
Insertion
Sort Efficiency
• Remember, the
insertion sort divides the data into a sorted and unsorted region. Initially,
the entire list is unsorted. Then, at each step, the insertion sort takes the
first item of the unsorted region and places it into its correct position in
the sorted region.
• With the first pass,
we make 1 comparison. With the second pass, in the worst case we must make 2
comparisons. With the third pass, in the worst case we must make 3 comparisons.
With the N-1 pass, in the worst case we must make N-1 comparisons. Therefore,
in the worst case, the algorithm makes the following comparisons:
1
+ 2 + 3 + ... + (N-1) which is: N*(N-1)/2
In
addition, the algorithm moves data at most the same number of times.
So, including both comparisons and
exchanges, we get N(N-1) = N*N - N
This
can be summarized as a O(N*N) algorithm
in the worst case. We should keep in mind that this means as our list grows
larger the performance will be dramatically reduced. In addition, unlike the
selection sort, in the worst case we have not only O(N*N) comparisons but also O(N*N) data moves.
For
small arrays - fewer than 50 - the simplicity of the insertion sort makes it a
reasonable approach. For large arrays -- it can be extremely inefficient!
Mergesort
Efficiency
• Remember, the
mergesort is a recursive sorting algorithm that always gives the same
performance regardless of the initial order of the data. For example, you might
divide an array in half - sort each half - then merge the sorted halves into 1
data structure. To merge, you compare 1 element in 1 half of the list to an
element in the other half, moving the smaller item into the new data structure.
•
Start by looking
at the merge operation. Each merge step merges your list in half. If the total
number of elements in the two segments to be merged is m then merging the segments requires m-1 comparisons. In
addition, there are m moves from the
original array to the temporary array and m
moves back from the temporary array to the original array. Therefore, for each
merge step there are:
3*m-1 major operations
• Now we need to remember that each
call to mergesort calls itself twice. How many levels of recursion are there?
Remember we continue halving the list of numbers until the result is a piece
with only 1 number in it. Therefore, if there are N items in your list, there
will be either log2N levels (if N is a power of 2) and 1+log2N
(if N is NOT a power of 2). Remember, each one of these calls requires 3*M-1
operations, where M starts equal to N, then becomes N/2. When M = N/2, there
are actually 2 calls to merge, so there are 2*(3*M-1) operations or
6(N/2)-2 =>>>>> 3N-2.
Expanding
on this: at recursive call m, there are 2m calls to re-merge where
each call merges N/2m elements, so it requires 3*(N/2m
)-1 operations. Which is the same as 3*N-2m . Using the BIG O
approach, this breaks down to O(N) operations at each level of recursion.
Because
there are either log2N or 1+log2N levels, mergesort
altogether has a worst and average case efficiency of O(N*log2N)
If
you work through how log works, you will see that this is actually
significantly faster than an efficiency of O(N*N). Therefore, this is an
extremely efficient algorithm. The only drawback is that it requires a
temporary array of equal size to the original array. This could be too
restrictive when storage is limited.
Quicksort
Efficiency
• Remember, the quicksort
partitions a list of data items that are less than a pivot point and those that
are greater than or equal to the pivot point.
• The major effort with the
Quicksort is the partitioning step. When we are dealing with an array that is
already sorted in ascending order and the pivot is always the smallest element
in the array, then there are N-1 comparisons for N elements in your array. On
the next recursive call there are N-2 comparisons, etc. This will continue
leaving the left hand side empty doing comparisons until the size of the
unsorted area is only 1. Therefore, there are N-1 levels of recursion and
1+2+...+(N-1) comparisons...which is: N*(N-1)/2. The good news that in this
case there are no exchanges.
Also,
if you are dealing with an array that is already sorted in descending order and
the pivot is always the largest element in the array, there are N*(N-1)/2
comparisons and N*(N-1)/2 exchanges (requiring 3 data moves each). Therefore,
we should be able to quickly remember that this is just like the insertion sort
-- and in the worst case has an efficiency of O(N*N).
• Now look at the case where we
have a randomly ordered list and pick reasonably good pivot values that divide
the list almost equally in two. This will require fewer recursive calls
(either log2N or 1+log2N
recursive calls). Each call requires M comparisons and at most M exchanges,
where M is the number of elements in the unsorted area and is less than N-1.
We
come to the realization that in an average-case behavior, quicksort has an
efficiency of O(N*log2N).
This means that on large arrays, expect Quicksort to run significantly faster
than the insertion sort. Quicksort is important to learn because its average
case is far better than its worst case behavior -- and in practice it is
usually very fast. It can out perform the mergesort if good pivot values are
selected. However, in its worst case, it will run significantly slower than the
mergesort (but doesn't require the extra memory overhead).
Tree Introduction
• Remember when we learned about
tables? We found that none of the methods for implementing tables was really
adequate. With many applications, table operations end up not being as
efficient as necessary. We found that hashing is good for retrieval, but
doesn't help if our goal is also to obtain a sorted list of information. We
found that the binary search also allows for fast retrieval, but is limited to
array implementations versus linked list.
Because of this, we need to move to more sophisticated implementations
of tables, using binary search trees! These are "nonlinear" implementations of the ADT table.
Tree
Terminology
• Trees are used to represent the
relationship between data items. All trees are hierarchical in nature which
means there is a parent-child relationship between "nodes" in a
tree. The lines between nodes are
called directed edges. If there is a
directed edge from node A to node B -- then A is the parent of B and B is a
child of A. Children of the same parent are called siblings. Each node in a
tree has at most one parent, starting at the top with the root node (which has
no parent).
Here
are some terms that might be useful:
Parent
of n The node directly above node n in the tree
Child
of n The node directly below the node n in the tree
Root The only node in the tree with no
parent
Leaf A node with no children
Siblings Nodes
with a common parent
Ancestor
of n A node on the path from the root
to n
Descendant
of n A node on a path from n to a leaf
Empty
tree A tree with no nodes
Subtree
of n A tree that consists of a child of
n and the child's descendents
Height The
number of nodes on the longest path from root to
a leaf
Binary
Tree A tree in which each node has at
most two children
Full
Binary Tree A binary tree of height h whose leaves are all at the level h and whose nodes all have two children;
this is
considered to be completely balanced
Binary
Tree Definition
• A binary tree is a tree where
each node has no more than 2 children. If we traverse down a binary tree -- for
every node -- there are either no children (making this node a leaf) or there
are two children called the left and
right subtrees (A subtree is a subset of a tree including some node in the tree
along with all of its descendants).
• The nodes of a binary tree will
contain values. For a binary search tree, it is really sorted according to the
key values in the nodes. It allows us to traverse a binary tree and get our
data in sorted order!
For
example, for each node n, all values
greater than n are located in the
right subtree...all values less than n
are located in the left subtree. Both subtrees are considered to be binary
trees themselves. Let's see what this looks like:

• A binary tree is NOT:
• Notice that a binary tree
organizes data in a way that facilitates searching the tree for a particular
data item. It ends up solving the problems of sorted-traversal with the linear
implementations of the ADT table.
• Before we go on,
let's make sure we understand some concepts about trees. Trees can come in many
different shapes. Some trees are taller than others. To find the height of a
tree, we need to find the distance from the root to the farthest leaf.
Or....you could think of it as the number of nodes on the longest path from the
root to a leaf.
Each of these trees has the same number of
nodes -- but different heights:

You will find that experts define heights
differently. For example, just by intuition you would think that the trees
shown previously have a height of 2 and 4. But, for the cleanest algorithms, we
are going to define the height of a tree as the following:
If a node is a root, the level is 1. If a
node is not the root, then it has a level 1 greater than the level of its
parent. If the tree is entirely empty, then it has a height of zero. Otherwise,
its height is equal to the maximum level of its nodes.
Using this definition, the trees shown
previously have the height of 3, 5, and 5.
• Now let's talk about
full, complete, and balanced binary trees. A full binary tree has all of its leaves at level h. In the previous
diagram, only the left hand tree is a full binary tree! All nodes that are at a
level less than the height of the tree have 2 children.
A complete
binary tree is one which is a full binary tree to a level of its height-1
... then at the last level, it is filled from left to right. For example:
This has a height of 4 and is a full
binary tree at level 3. But, at level 4, the leaves are filled in from left to
right! From this definition, we realize that a full binary tree is also
considered to be a complete binary tree. However, a complete binary tree does
not necessarily mean it is full!