CS163 Data Structures
Week #3
Notes
Stacks
and Abstract Data Types
• Chapter 6 - Stacks
• The stack as an example of an Abstract
Data Type in Program Development
• ADT Stack Operations
• Implementing Stacks using arrays
• Implementing Stacks using dynamic memory
Queues and Abstract Data Types
• Chapter 7 - Queues
• The Abstract Data Type Queue
• Implementations of the ADT
Queue
Implementing
ADT's
• Now that you understand what an ADT is, let's talk about the data structures used in the implementation
of an ADT!
• First, we will examine implementing
an ADT Ordered List. Here, we can insert and retrieve items from the list by
their corresponding position (or location) in the list.
Our
first thought might be to implement an ADT Ordered List using an array. It
seems natural since both the array and an ordered list reference its items by
position number. Thus, you can store the ordered list ith item in array items[i].
This array would be implemented as a data member.
If
this is the case, we need to consider how much of the array the ordered list
will occupy. Since it will probably not fill the entire array, we need to keep
track of the array elements that have been assigned to the ordered list...and
which ones are available for use in the future. To do this we simply keep track
of the number of items in the list, assuming there is a maximum length defined
for the list.
Then,
each ADT operation should be implemented as a member function. When definition
the member functions, think about the arguments you might need. If you
implement the ADT using the class construct, consider whether or not you need
to pass the array as one of the arguments. What about the length of the list?
These considerations should be part of your design...and determined way before
you begin implementation!
Therefore,
our first attempt at an ordered list declaration might look like:
const
int maxlen=100;
class
ordered
{
public:
//
place the constructor here...to perform all initialization steps
//
place the prototypes for the member functions here
private:
int
length;
int
items[maxlen];
};
Then,
in my main(), I can create as many ordered lists as is desired by saying:
ordered list1;
ordered list2, list3; //etc.
• Our design for each of the ADT
operations is:
For
Initialization:
Initialize
the length data member to zero
To
find the length of the list:
Return
the value of the length data member
To
insert an item at a specified position:
First,
perform some error checking to make sure that the specified position is valid.
Make sure that the specified position is not beyond the maximum length of the
list; if it is report an error. Also, make sure that the position requested is
not less than zero; if it is report an error.
Next,
since we are working with an array data structure, we must consider shifting
all of the data items to the right that have positions greater than the
specified position. We only need to shift these data items up by one.
Lastly,
we insert the new data item at the specified location. This data item must be
specified as an argument to the insert member function. And, we update the
length for this particular ordered list by increasing it by one.
To
delete an item at a specified position:
First,
perform some error checking to make sure that the specified position is valid.
Make sure that the position requested is not less than zero; if it is report an
error. And, make sure that the specified position represents a data item that
has already been inserted; this can be done by comparing the specified position
with the current length of the list.
Next,
since we are working with an array data structure, we must consider shifting
all of the data items to the left that have positions greater than the
specified position. We only need to shift these data items up by one. This
takes care of the "delete" operation.
Lastly,
we update the length for this particular ordered list, by decreasing it by one.
To
retrieve an item from the list...at a specified position:
First,
perform some error checking to make sure that the specified position is valid.
Make sure that the position requested is not less than zero; if it is report an
error. And, make sure that the specified position represents a data item that
has already been inserted; this can be done by comparing the specified position
with the current length of the list.
Next,
return to the client the data item located at the specified position in the array. Remember...the client
shouldn't know that we are using an array
to implement our ordered list ADT!
• Alternatively, we could implement
this scheme using pointers. This solves the problem of running out of room
because we can allocate memory dynamically as we need it. Arrays are really not
good for ordered lists since they can't allow the list to exceed the fixed size
of the array.
Implementing
Abstract Data Types...using dynamic memory
• Now, let's look at an implementation of dynamic memory
allocation for an ADT of an Ordered List. We will use the techniques learned in
CS162 to link nodes (allocated using new)
together, creating a linked list that represents the ADT Ordered List. As the
length of the ordered list increases, you only need to use new to allocate new nodes
for additional items. Unlike using arrays, using pointers does not impose a
fixed maximum length on the size of the list (unless of course you run out of
memory!).
• Therefore, our first attempt at an
ordered list declaration might look like:
struct
node
{
int data;
int
*link;
};
class
ordered
{
public:
//
place the constructor here...to perform all initialization steps
//
place the prototypes for the member functions here
private:
int
length;
node
*head;
node
*current;
};
• Now let's look at the design considerations
for some of the operations performed on the ordered list:
For
Initialization:
Initialize
the length data member to zero
and
we must initialize our pointers to NULL!
To
find the length of the list:
Return
the value of the length data member
• Now think about the retrieve,
insert, and delete operations. Consider adding another function which returns a
pointer to the node at a specified position in the list. This will reduce
duplication of code. Why? Because a linked list does not provide direct access
to a specified position. Therefore, this new function (let's call it setptr), must traverse the list from its
beginning until the specified point is reached. As you will see, this task is
common to the implementation of retrieve, insert and delete. Notice performance
issues....with arrays we were restricted to a fixed number of elements that can
be in our ordered list...but we could very quickly access each of the array
elements...without traversing the list!
• Here are the design considerations
for setptr:
To
traverse to a position in the list:
Goal:
To return a pointer to the node at a given position in the ordered list; if the
position is invalid, returns NULL.
First,
perform some error checking to make sure that the specified position is valid.
Make sure that the position requested is not less than zero; if it is return
NULL. And, make sure that the specified position represents a data item that
has already been inserted; this can be done by comparing the specified position
with the current length of the list.
Next,
begin at the head of the list and traverse the specified number of times to the next node. Once the ith position is reached, return the pointer to that node.
To
retrieve an item from the list...at a specified position:
First,
perform some error checking to make sure that the specified position is valid.
Make sure that the position requested is not less than zero; if it is report an
error. And, make sure that the specified position represents a data item that
has already been inserted; this can be done by comparing the specified position
with the current length of the list.
Use
setptr to traverse to the specified position. Return the data item at that location...if the pointer is not
NULL.
(This
is substantially less efficient than the array implementation...since we can't
access the specified element directly.)
To
insert an item at a specified position:
First,
perform some error checking to make sure that the specified position is valid.
Make sure that the specified position is not beyond the maximum length of the
list; if it is report an error. Also, make sure that the position requested is
not less than zero; if it is report an error.
If
we are going to insert an item at the first location, we need to insert the new
item at the beginning of the list (you learned how to do this in CS162!)
Otherwise,
use setptr to traverse to the node before
the specified position. Insert the new item after this node.
• On your own...write the design
considerations for delete.
• Thinking about
"walls"...because setptr returns a pointer you would not want any
module outside of the ADT to call it; otherwise the "walls" around
the ADT would be violated. The key is that your modules should be able to use
the ADT without knowledge of the pointers that the implementation uses. Thus,
only retrieve, insert, and delete should call setptr....and it should be hidden from the user. In addition,
arguments should be selected for retrieve, insert, and delete that do not bind
the user to either an array implementation or a linked list implementation!
• Make sure to compare approaches.
Usually various implementations of an ADT have advantages and disadvantages
which must be weighted when deciding which one to use. When comparing arrays versus
dynamic memory allocation, our trade off is search speed versus memory
limitations.
The
approach we used with arrays was easy to implement. It behaves just like an
ordered list and we can quickly find items. But, the array has a fixed size.
When choosing how to implement an ADT, you must decide if the fixed-size
restriction is a problem for your particular application. The answer is based
on whether or not your application can predict in advance the maximum number of
items in the ADT at any one time; if it can't, then using arrays is not
adequate. In addition, if you CAN predict in advance the maximum number of
items, you need to consider if you are willing to waste storage by declaring an
array to be large enough to hold the maximum number of items. If the maximum
number of items is very large, but this case rarely occurs (like a maximum of
1000 where the list usually only has 10 items!). In this case you must reserve
space for all 1000 items even if you are "wasting" 990!
For
such storage considerations, the dynamic method is preferable...since it only
provides as much storage as the list needs. You don't need to predict the
maximum size and you will not be wasting storage. But, what about implementing
this with a dynamically allocated array? This might actually be the best of
both worlds!
Other
things to consider: If you are able to determine the maximum size, using arrays
will actually save space because it does not have to store explicit pointer
information. When dealing with large lists, this could save significant memory!
And, provide faster access time!! This is called "direct access".
• As you may have already realized,
the beauty of implementing our list using the concept of ADT's is that you can
change from one implementation to another without impacting the rest of your
program! You should be able to change from an array implementation to one using
linked lists! Because the "wall" created by data abstraction isolates
the rest of the program from how you implement an ADT, changing from one
implementation to another should not require changes to you program.
ADTs:
In Summary
• Remember that data abstraction is a
technique for controlling the interaction between a program and its data
structures and the operations performed on this data. It builds
"walls" around a program's data structures. Such walls make programs
easier to design, implement, read, and modify.
• Abstract Data Types are the
specification of the operations to manage your data .. together with the actual
data values
• Only after you specify your ADTs
should you begin to think about implementing the data structures. Remember that
your program should not depend on HOW your ADT is implemented!
Stacks
• Stacks are considered to be the
easiest type of list to use. The only operations we have on stacks are to add
things to the top of the stack and to remove things from the top of the stack.
We never need to insert, delete, or access data that is somewhere other
than at the top of the stack.
Think
of a stack as a pile of paper on a desk. For example, let's think of a stack as
a pile of quizzes; as each of you turns in your quiz...the quiz gets added to
the top of the stack. When I grade
them, I take them off of the stack, one at a time starting from the top! This
means that the last quiz placed on the top of the stack will be the first quiz
graded! This is called last in -- first out (abbreviated: LIFO)! Using stacks,
I can't go and take the quiz at the bottom or from the middle; I must always
start from the top.
• When we add things to the top of the
stack we say we are pushing data onto
the stack. When we remove things from the top of the stack we say we are popping data from the stack.
• Many computers implement function
calls using a mechanism of pushing and popping information concerning the local
variables on a stack. When you make a function call, it is like pushing the
current state on the stack and starting with a new set of information relevant
to this new function. When we return to the calling routine, it is like popping;
the information concerning the execution of the function is lost!
• When implementing the code for a
stack's operations, we need to keep in mind that we should have functions to
push data and to pop data. This way we can hide the implementation details from
the user as to how these routines actually access our memory...why? because you
can actually implement stacks using either arrays or using linked lists with
dynamic memory allocation.
• There are five important stack
operations:
1)
Determine whether the stack is empty
2)
Add a new item onto the stack...push
3)
Remove an item from the stack...pop
4)
Initialize a stack (this operation is easy to overlook!)
5)
Retrieve the item at the top of the stack...without modifying the stack
•
Let's draw what a pointer-based
stack implementation looks like:
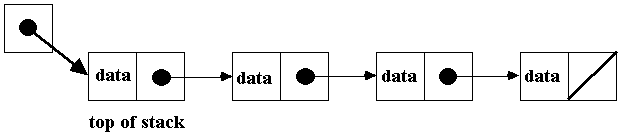
•
What are the differences between
this and the array based implementation?

Array
Implementation of Stacks
• Remember that with an array
implementation, we are restricted by the size of the array. This limits the
number of push operations we can do; we can't add an item to the stack if the
stack's size limit has been reached. If this restriction is not acceptable,
then you shouldn't implement your stack using arrays...think about dynamic memory
as an alternative.
• With our first implementation of a
stack, we will represent a stack as a class, which contains the array of items
and an index to the top position in the array:
const
int maxlen=100;
class
stack
{
public:
//
place the constructor here...to perform all initialization steps
//
place the prototypes for the member functions here
private:
int
top;
int
items[maxlen];
};
• Now we are ready to design the ADT
operations on the stack using arrays:
To
Initialize a stack:
We
must set the top of the stack to zero.
To
determine if the stack is empty or not:
(Return
TRUE if the stack is empty, FALSE otherwise.)
Check
if the stack's top is zero. If it is return TRUE if it is not return FALSE!
To
Push a data item onto a stack:
(Modify
the stack with the new item specified, if the stack isn't full. If the stack is
full then nothing should be done and a FALSE flag should be returned.)
First
check is the top of the stack is greater than or equal to the maximum size allowable.
If it is return FALSE.
Otherwise,
increment the top of stack and add the new item to the array at that location.
Return a TRUE flag...meaning success.
To
Pop a data item off of the stack:
(If
the stack is not empty, then the item at the top of the stack is removed and
success is TRUE; otherwise, deletion is impossible and success is FALSE.)
If
the stack is empty, return FALSE. Otherwise, decrement the top of stack and
return TRUE.
Advantages
• We should remember that when we use
ADT operations, we can very easily change the way in which we implement the
code. Only the definition of the class and the implementation of the member
functions must be altered...nothing else!
• In addition, just seeing the words
push and pop in a routine will immediately tell anyone reading the code that
you are using a stack data structure. Self documenting!!
• Lastly, separating the use of data
structures from their implementation will help us improve the top-down design
of both our data structures and our programs.
• There are many ways to design ADT
operations, with different user interfaces depending on your objectives. There
is nothing magical about the routines implemented in the previous example.
There are a variety of ways to define the ADT operations. To a large extent,
these different ways reflect style differences and coding standards.
Pointer-based
Implementation of Stacks
• Many applications require a pointer-based implementation of a
stack.
So that the stack can grow and shrink
dynamically!!! It isn't limited in size like an array.
• The pseudo code necessary to
implement a pointer-based implementation is as follows. The data structure
would be defined as:
struct
node
{
int data;
node
*link;
};
class
stack
{
public:
//
place the constructor and public prototypes here...
private:
int
length;
node
*head;
node
*current;
};
• The design of our ADT operations
would look like:
For
Initialization:
Initialize
the length data member to zero
and
we must initialize our pointers to NULL!
(Think
about whether or not you really need a length??)
To
determine if a stack is empty:
One
approach would be to check if the length is zero. Another approach would be to check if the head pointer is
NULL!
To
Push a data item onto a stack:
Allocate
memory for a new node. Save the data item in this node.
Then,
connect the link pointer to the
previous top of stack...because we now
have a new top of stack. And, lastly, update the head pointer to point to this new node.
But...is
this complete? Would we need to consider the case when the stack is empty to begin with?? Think
about it!
To
Pop a data item from a stack:
If
the head pointer is NULL, then there is nothing to pop and deletion is
impossible; in this case our success is FALSE.
Otherwise,
return to the user the data item that was on the top of stack and deallocate
the the top of the stack memory. Remember to update the head pointer to now
point to the second item...the new top of stack. To perform these tasks you
will need a temporary pointer...why?
• Notice with a linked list
implementation we are not concerned about the stack being full.
• In addition, when using a linked list for stacks, we need
to determine whether the beginning or the end of the linked list will be the
top of the stack. As you can see, we have implemented the stack with the top at the beginning of the list. What is the
draw back of using the tail of the list? How would pop be implemented? Notice,
pop would have to trace all of the way from the head of the list to find out
what the new top of stack would be. And, in order to easily add nodes to the
end of the stack, we would need to keep an end of stack pointer.
• Notice that using the beginning of
the list as the top of stack, the only information we need to keep track of is
the location of the top...which is the pointer to the list of linked nodes!
Queues
• We can think of stacks as having only one
end; because, all operations are performed at the top of the stack. That is why
we call it a Last in -- First out data structure. A queue, on the other hand,
has two ends: a front and a rear (or
tail). With a queue, data items are only added at the rear of the queue and
items are only removed at the front of the queue. This is what we call a First
in -- First out structure (FIFO). They are very useful for modeling real-world
characteristics (like lines at a bank).
• When establishing a
queue data structure, we must consider specifying our Queue Abstract Data Type
Operations.
For example, the Queue ADT Operations
could be:
Create -- creates an empty queue
IsEmpty -- determines if the queue is empty
EnQueue -- adds an item to the rear of the queue;
DeQueue -- remove from the
queue the item at the front
QueueFront -- retrieve the item at the top of the queue without modifying
the queue itself.
Implementations
of the ADT Queue: Circular Array
• Just like with
Stacks, there are choices in how to implement queues. You might choose either
an array based implementation or a pointer based implementation. First, we will
examine an array based implementation; later we will examine a pointer based
implementation.
• If we choose arrays,
the size of our queue is fixed. Our first attempt at an array based
implementation might start with a data structure such as: (Assume that our queue consists of integer
values.)
const int MaxQueue=100;
class queue
{
public:
//member functions
private:
int front; //index to the front of the queue
int rear; //index to the rear of the queue
int items[MaxQueue+1]; //queue of data items
};
We might first initialize the front to 1
and the rear to 0. When a new item is added to the queue, rear is incremented
and the item placed at the index of rear.
When an item is removed, front is incremented. The queue is empty when rear < front. The queue is full when
rear = maxqueue. Let's draw a
picture. Does anyone see a problem with this?
• Yes, this results in
a rightward drift. After a sequence
of data items are added and removed, the queue will drift to the end of the
queue; you might get to the point where rear might even equal maxqueue even
when there are only a few items in the queue!

• One possible
solution is to shift the array elements to the left after each deletion or
whenever the rear reaches the end of the queue (rear = MaxQueue) We call this a linear implementation of a queue.
It is not very efficient since most of the time would be spent shifting data
items.
• A much better
approach -- and the one we will concentrate on today -- is to use a circular
array. With a circular approach, we advance the front to remove an item...and
advance the rear to add an item. But, when either front or rear advances past
the MaxQueue location, it wraps around and starts all over at location 1. This
wrap around gets rid of the problem of rightward drift.
• The main difficulty
with this approach is in determining if the queue is empty or full. We can
simplify this by knowing that the queue is either empty or full when front is
one position ahead of the rear. The problem is that we can't distinguish
between empty or full this way.
• Therefore, we will
also keep a counter of the number of items in the queue. Before adding an item
to the queue, we can always check to
see if the count is equal to the MaxQueue size; if it is, the queue is full.
Before removing an item from the queue, we should check to see if the count is
zero; if it is, then we know the queue is empty.
• Using this method,
our declarations would be:
const int MaxQueue=100;
class queue
{
public:
//member functions
private:
int front; //index to the front of the queue
int rear; //index to the rear of the queue
int items[MaxQueue]; //queue of data items
int size; //current number of data items in the
queue
};
• We need to first
initialize front to 1; and rear to MaxQueue; and size to 0; this will be done
in our constructor.
• To add a new item to
the queue, we want to first increment rear, then add the item at rear's
position. We can automatically get the wraparound effect by using % operator
(mod). Therefore, to add a new item to the queue we need to:
rear = (rear % MaxQueue) +1;
items[rear] = new_data_item;
size++;
• Notice that if rear
equals MaxQueue --- (rear % MaxQueue is zero),
the new rear would be 1!!
• To remove an item
from the queue we need to:
front = (front % MaxQueue) +1;
size--;
• The following
attempts to implement our Qtack ADT operations using a circular array. Here is
our algorithm:
Constructor: When a queue object is
defined, we want to initialize the front, rear, and size data items. Front is
set to index 1, rear to index MaxQueue, and size to zero. You might want to
consider default arguments as an alternative, and allow for a dynamically
allocated array of integers of user-defined size!
IsEmpty: To determine if the queue is
empty, the size is compared with zero. If size is zero, true is returned;
otherwise, false is returned.
EnQueue: Before an item can be added to a
queue, we must check whether or not the queue is already full. Therefore, size
must be compared with MaxQueue; if it is greater than or equal to MaxQueue then
a failure flag must be set and returned. Otherwise, the new item (supplied as
an argument) is added to the queue. To do this, we first increment the rear
index, save the data items at that location in the array, and increment the
size by one. Don't forget to set a success flag to true!
DeQueue: Before an item can be removed
from a queue, we must check whether or not the queue is empty. If the size is
zero, then a failure flag must be set and returned...because our queue is
empty! Otherwise, the front of the queue should be incremented and the size
decremented by one. Don't forget to set a success flag to true!
Implementations
of the ADT Queue: Pointer-based
• Now implement the Queue ADT operations
using dynamic memory.
• For queues, we will
see that the pointer-based implementation is more straightforward than the
array method. And, it doesn't restrict us to a fixed size queue.
• There are two ways to
implement a Queue ADT using pointers...using two external pointers or using a
circular linked list.
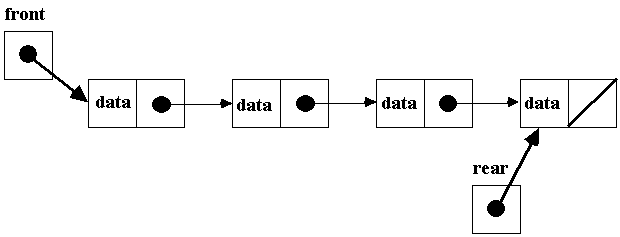 Or,
Or,
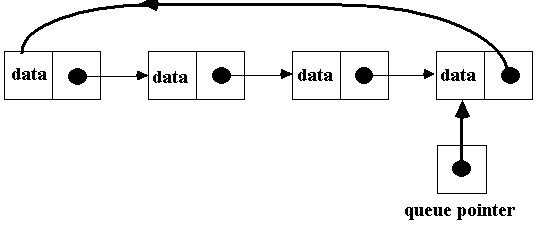
• Using a circular
linked list, we can get away with only having one pointer; we no longer require
front and back pointers. Our queue pointer points to the node at the rear of
the queue to begin with. And, our queue pointer's "link pointer"
points to the node at the front.
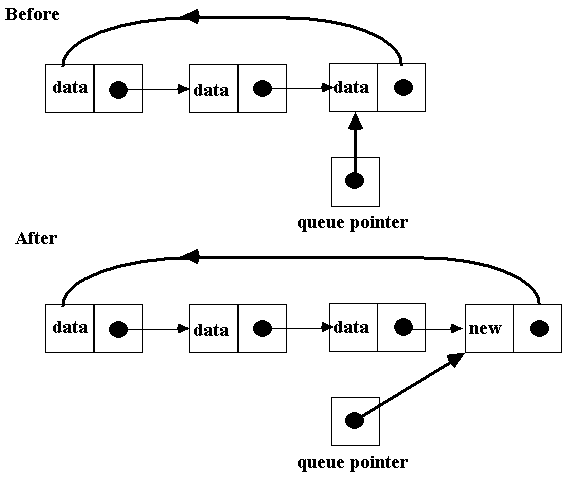
• Insertion and
deletion are straightforward. To insert a node we need to do the following:
1) allocate memory for the new node
2) change the new node's link
pointer
3) change the queue pointer's link
pointer (i.e., the rear node)
4) update the queue pointer to point
to the new node
• Before we get into
the code to do this...deskcheck the algorithm for all boundary conditions; for
example, does this algorithm work when the queue is empty?
As
shown:
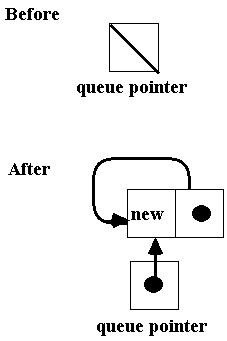
• Deletion is simpler
than insertion. Items are deleted at the front of the queue (versus inserting
at the rear). We only need to change one pointer! However, make sure to
consider the special case when there is only one item in the queue. In this
case, our queue pointer needs to be reset to NULL.
• The class for a pointer-based
implementation of a queue might resemble:
struct node {
int data;
node * link;
};
class queue {
public:
//member functions
private:
node *queue_ptr; //points to the rear of the queue
};
• Using a circular
linked list to create the Queue ADT operations:
Constructor: When a queue object is
defined, we want to initialize the queue_ptr to NULL. No memory needs to be
dynamically allocated until a node is added to the linked list!
IsEmpty: To determine if the queue is
empty, the queue_ptr is compared with zero (NULL). If it is NULL, true is
returned; otherwise, false is returned.
EnQueue: To add the new item (supplied as
an argument) to the rear of the queue, memory must first be allocated for a
node. Then, the data supplied as an argument must be saved in that node. If the
queue is empty, then this new node's link pointer should point to itself.
Otherwise, this new node's link pointer should point to the front of the queue
(queue_ptr's link). Then, the previous rear of the list should be altered to
point to this new node. And lastly, queue_ptr must be updated to point to the
new rear of the list.
DeQueue: Before an item can be removed
from a queue, we must check whether or not the queue is empty. If queue_ptr is
NULL, then a failure flag must be set and returned...because our queue is
empty! Otherwise, implement the following steps:
a) define a temporary pointer to a
node
b) set this pointer to the front of
the list
c) if there was only one node in the
list, then set the queue_ptr to NULL;
d) otherwise, set queue_ptr's link
value to point to the new front of the list
e) deallocate the memory; pointed to
by our temporary pointer.
f) return success!