Program Design Methodology
CS 161: Introduction to Computer Science 1
Program Design Methodology
• Programming is really all about solving
problems...but we use a computer to do that for us! With small problems -- you
may be able to get away with just thinking of the solution to the problem in
your head.
• In fact, many of you
probably are writing your algorithms as an after thought instead of using an
algorithm as a road-map to actually solving the problem by breaking it down in
to major tasks & then subtasks. And not coding until we could get down to
very fine detail of those subtasks FIRST WITH WORDS/Pseudo code.
• However, as we
progress we will be concentrating on solving larger problems where the first
step MUST be to design an algorithm to break down the problem in to sub-tasks
and then we will implement the subtasks one at a time!
• Therefore, in order
to solve the problems on a computer -- we must know how to design good
algorithms. You all know what a basic algorithm is ... but now we have to
concentrate on getting good at it! Because if you do your algorithm wrong
(i.e., you go about solving the problem incorrectly)...then you might get the
whole program wrong! When dealing with a big project where there may be
multiple engineers developing code for one big program -- picking the wrong
solution could lead to schedule delays...budget overruns...and overall your
bosses lack of confidence in your work!
• Once you have an
algorithm that REALLY WORKS - then programming is a very simply task - dealing
primarily with the syntax we have been learning.
• The only problem is
that designing algorithms is a very creative process...and might even be
considered to be an artform. It is patterned after how we think...so that no
two algorithms for a complex program will be alike!
• None the less - there
are some basic steps we should be very familiar with when solving a problem and
writing an algorithm. There is no guarantee that by following these steps you
will create an accurate algorithm ... but it should help you to take the
problem a step at a time and break it down into bite size pieces!
• Steps to Developing an Algorithm
First....
• Make sure you have a
complete specification. Look at what the specification states...does it make
sense? Is it clear? When you read it do you have questions.
• Double check that the
specification clearly outlines what input into the program is required...and
what its format is (is all of the data on one line). Look at what output is
required...is it completely defined?
• Next look at error
conditions. Under what cases does the specification require error messages -
and how should they appear. What type of data is correct versus incorrect? Should the program compute answers even if
the data is incorrect?
• Make sure you know
how the program should act when it ends. Is there a final message that gets
printed to signify that the end of the program has been reached?
• Once you've made a
list of all of the problems and questions you can come up with the
specification -- go to your instructor, supervisor, or project leader and get
them ironed out. Either participate with rewriting the specification or request
that a new specification be provided that covers all of your concerns.
• So - Having a
COMPLETE, CONCISE, and CORRECT specification is a NECESSARY first step!
Ensuring this will enable you to not leave out vital information in your
program.
Next....
• Formulate a precise
statement of the problem to be solved by the algorithm.
• Break the problem
into subproblems (subtasks).
• For each subtask...
... formulate a precise statement of the problem the
subtask is to solve
... use existing algorithms if they have already been
developed
... Or, use standard techniques for solving the problem
if they exist
... design the data structure necessary to organize the
data involved
... write out each step of the subtask in english/pseudo
code. These
steps should be at such a low level that it
is clear how to develop
a C++ program to do each step. The solution at this
point for each step you write out should be
very obvious.
Then....
• When implementing the
C++ code -- the modules (functions) designed should match the major subtasks
developed!
• When a problem is
divided into subtasks --- you can design algorithms for each subtask -- and
therefore code and debug each subtask separately. This way we can test/debug a
portion of the entire problem a step at a time to make sure that we are
correctly solving each step.
• This approach is
called procedural abstraction - where we build functions that match our major
subtasks -- which can become self-contained subpieces. Once they are designed
and debugged - we no longer have to worry about their inner-workings and can
just be concerned that we know what their (a) purpose is, (b) input parameters
are, and (c) output parameters are.
Now Let's Look at an Example --- Let's design an
algorithm:
1. What if our problem specification was:
Write a modular program that maintains a database of
bibliographic references in the form Author, Title, Journal, Volume, Page,
Year. There may be 40 characters in the Author's name, in the book Title, and
in the Journal's name. The Volume, Page, and Year are all integers. Design a
program that allows users to enter a list of references, view the list, search
for a desired reference by author or title, and delete references.
2. So, our first step is to make sure our
specification covers everything we need to know inorder to design an algorithm:
• What about error checking?
• How does the user indicate what task he wants to do?
• Does this program run forever or is there a way to terminate
it?
• What type of message should be printed at the end of the
program?
• When responding to a request to view the list -- how should
it appear?
• How many references can be in our database?
3. Once we get answers to these questions, it is
time to start designing our algorithm. Let's first precisely state what the
program will do:
Maintain a database of bibliographic references
which can be interactively modified (references added, deleted), viewed, or
searched.
4. The major tasks would be:
1. Introduce the user to our interactive bibliographic
references program
2. Find out what the user wants to do: Enter a reference, View
all references, View a specific reference,
Delete a reference, or quit.
3. Either ...
a. Enter a reference,
b. View all references,
c. View a specific reference,
d. Delete a reference, or
e. If the user wants to quit, provide a shut down message
and thank him for using
our system!
4. Unless the user wants to quit -- continue with Step #2.
5. Now let's break this down into subtask...
6. And, design the data structures
• Once the algorithm is
designed...it is time to test it. Choose test data that will expose any
possible errors. Use boundary values -- using the largest and smallest possible
values allowable. Use erroneous data and see if the correct results occur.
Double check that all of your loops iterate the appropriate number of times.
Make sure that all cases are fully exercised. A good rule of thumb is to design
(YES DESIGN!) your tests to execute every line of code in addition to checking
the above conditions.
• After we fully test
and fix our bugs (called debugging), we should look at our code and verify that
it is indeed portable. Since programs
represent a large investment in programming time, it really does pay to make
sure it will work on a variety of computers. One way this is done is to use
standard C++ syntax and not tricks that may be available on one system but not
on another. This doesn't ensure
portability, but it is a step in the right direction.
• This means we should
not assume that our system automatically initializes our variables to zeros or
blanks. We should ALWAYS explicitly initialize our variables.
• When you do need to
use a feature that is depending on a particular computer, try to isolate it in
a particular module so that when you have to maintain the program, or port it
to another system, you can easily see what portions have to be touched. It is
always a good idea to treat input/output using this approach.
Software Engineering
• In this class are
programs are very small in comparison to the development of most industry
software systems. In industry - a large amount of planing needs to be done
before any code is written down. Plus - the software isn't DONE when you think
you are finished debugging. Customers need to take a look at the code (maybe
called alpha/beta release) and see if it really meets their needs. Then the
code needs to be officially released, maintained, and then will evolve as
customer's needs change and develop.
• This development
process is actually called the software life cycle. It has phases of:
Specification
Design
Implementation
Testing
Alpha/Beta Release
Revision/Testing/Debugging
Release of Software & Documentation
Maintenance
Evolution
Obsolescence
• The first step is to
decide what exactly the system is supposed to do. This is resolved with the
development of the specification. To create the specification customer's need
to be contacted and market research may need to be performed to find out what
is needed/desired/wished. Some of these things may be doable -- others may not
be. Customer's may only have a vague idea of what they want done -- so asking
the right questions is important...they may know little about computers and/or
software!
• To develop a
specification, you need to find out what the input/output is, what task is
required to be performed, what error conditions will/can occur, what type of
documentation is required (e.g., a user's manual?), How fast should the system
be? How often will it need to be changed? etc.
• So, the specification
for a software system indicates WHAT the system will do. The design of the
system indicates HOW it will do it. This stage may be similar to our
algorithms!
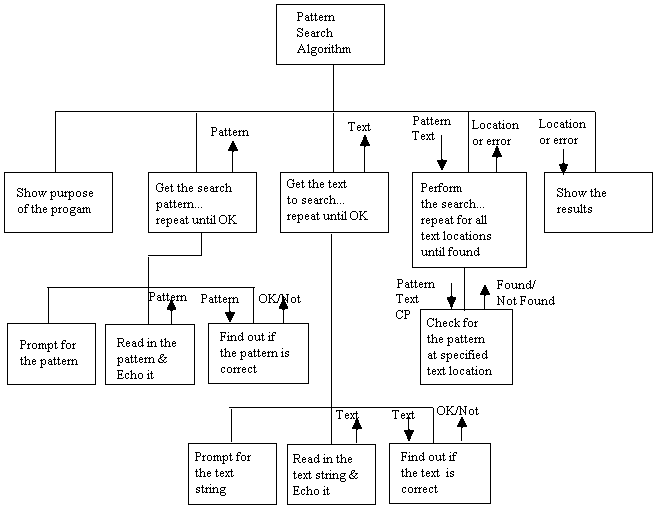
Introduce Structure Charts
• A structure chart can
be considered a hierarchy diagram.
• Let's first take a
look at a hierarchy diagram; it represents the breakdown of the algorithm into
five main tasks. The tasks are imagined as executing in order from left to
right:
Problem: Design an algorithm that reports
the first position of a given pattern string within a given text string. If no
pattern is found print out an error message. Before we design the algorithm -
let's be clear how the input and output should appear:
For example, the prompts and input might
be:
Pattern: ful
Text: Wonderful
The output might be:
Pattern found at position 7
Or, or example, the prompts and input
might be:
Pattern: full
Text: Wonderful
The output might be:
Error: The pattern was not
found in the text string.
• Given this, now we
are ready to start out algorithm:
Step 1: Announce the purpose of the
program
Step 2: Prompt (ask) for, read, &
echo the pattern for which to search
Step 3: Prompt (ask) for, read, &
echo the text string to be searched
Step 4: Search the given text for the
first occurrence of the given pattern
Step 5: Display the results and/or error
message
• These five tasks
could be shown in the form of a hierarchy diagram: (called the first stage)
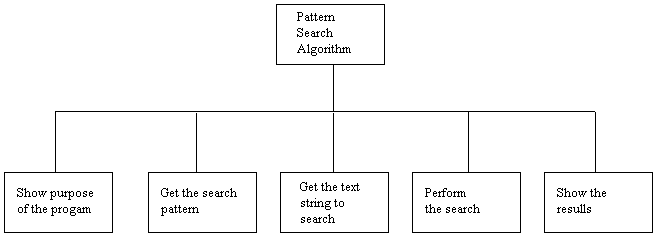
• Then, we break down each of the tasks into
subtasks. For example, Task 2 might be:
2a. Prompt for the pattern for which to
search
2b. Read the pattern from the keyboard
2c. Echo the pattern to the user
2d. Find out if this is the correct
pattern...if not, read in a new pattern (2b)
• So, the second stage
- breaking our subtasks down one more level would create a more complete
hierarchy diagram....this evolves as we begin to plan the flow of data from one
part of the diagram to another.
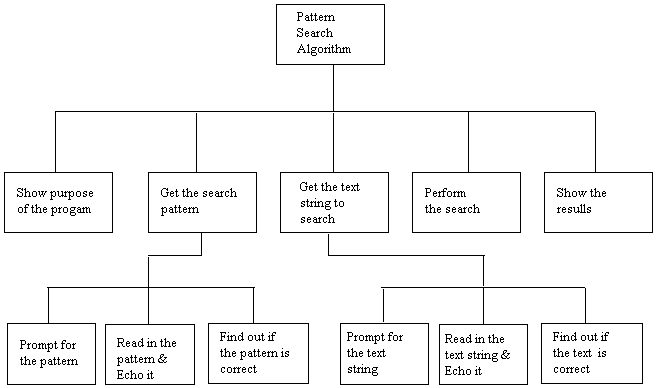 •
Then...let's show the data flow for each of these blocks:
•
Then...let's show the data flow for each of these blocks:
• Using this approach,
the overall problem is attacked first by breaking it down into smaller
problems. These smaller problems are dealt with later, by breaking them down
into still smaller ones. This process continues until the remaining problems
are trivial
• Hierarchy means that
we use a layered structure, where items are ranking one above the other. For
each of the layers you could consider using functions
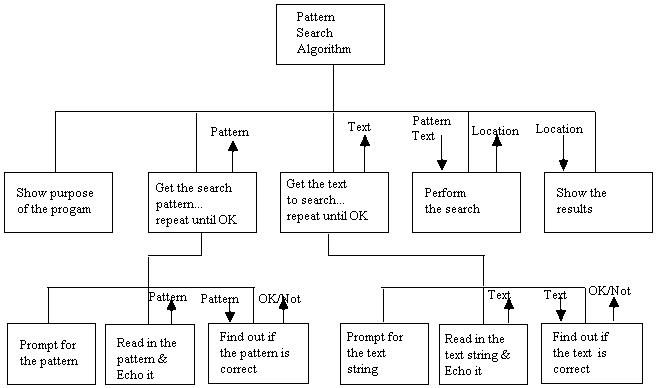
• Look at the next
task: task 4. This is where the pattern is searched. As we did before - let's
break it down starting at the top. In order to get started, think about how you
would search the text for the pattern if you were doing it in your head. You
would look through the text, checking each character position for the beginning
of an embedded copy of the full pattern. Your outline might look like:
4a. check for the pattern at the first
character position of the text;
if the entire pattern is found,
starting at that position,
then quit searching and report the pattern is found at the
first position
otherwise, continue with step 4b.
4b. check for the pattern at the next
character position of the text;
if the entire pattern is found, starting
at that position,
then quit searching and
report the pattern is found at that position
otherwise, continue with step 4b.
(Continue for each character position)
• Since this is a
repetitive process, we might do better by describing it as:
4. For each character position in the
text string:
a. check for the pattern,
if the entire pattern is found,
starting at that position,
then quit searching and
report the pattern is found at that position
otherwise, advance to the next
position and repeat step 4a
b. If the entire text string was
searched and the pattern was not found,
report an error.
• This is close, but
not complete. It doesn't include the detail necessary to check for the presence
of the pattern at a particular position. So, we need to break this problem down
even further. We need to check for the presence of a pattern by checking for
each of its characters in order. Of course, if there are fewer characters
remaining in the text beyond the current position than there are characters in
the pattern, the pattern cannot be in the text at that position.
• Given these thoughts,
now let's design the algorithm for task 4 (its more complicated than you
thought - huh?):
Function
for checking for the pattern at a particular position in the text string:
a. If there are fewer remaining characters in the
text than there are in the pattern, ...
... then report that the pattern
was not found at the current position
b. Otherwise, for each character in the
pattern...
... compare the pattern character
to the corresponding text character
... if it is not identical,
return that the pattern was not found at the
current position
... Otherwise, continue checking
c. If all characters were found to be
identical...
... report that the pattern was
found at the starting position
Otherwise report that it was not
found
With these steps...we
add the following box to our diagram: