Portland State University
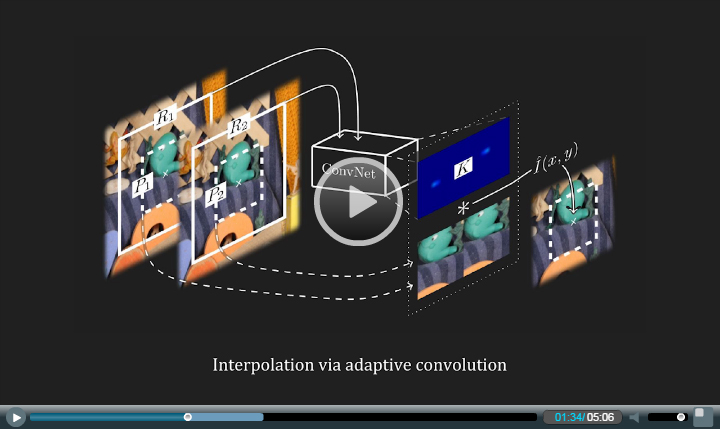
Video frame interpolation typically involves two steps: motion estimation and pixel synthesis. Such a two-step approach heavily depends on the quality of motion estimation. This paper presents a robust video frame interpolation method that combines these two steps into a single process. Specifically, our method considers pixel synthesis for the interpolated frame as local convolution over two input frames. The convolution kernel captures both the local motion between the input frames and the coefficients for pixel synthesis. Our method employs a deep fully convolutional neural network to estimate a spatially-adaptive convolution kernel for each pixel. This deep neural network can be directly trained end to end using widely available video data without any difficult-to-obtain ground-truth data like optical flow. Our experiments show that the formulation of video interpolation as a single convolution process allows our method to gracefully handle challenges like occlusion, blur, and abrupt brightness change and enables high-quality video frame interpolation.
IEEE CVPR 2017. PDF (spotlight)
Note: After the publication of our paper, we recently found that the idea of estimating spatially-varying linear filters to transform an image for many computer vision tasks was explored by Seitz and Baker in their ICCV 2009 paper "filter flow". It would have been nice to cite and discuss their "filter flow" paper in our work. We encourage others to cite Seitz and Baker if your work builds upon the idea of estimating spatially-varying linear filters for image transformation / synthesis.
IEEE CVPR 2018. PDF
Simon Niklaus, Long Mai, and Feng Liu. Video Frame Interpolation via Adaptive Separable Convolution.
IEEE ICCV 2017. PDF Code
This work was supported by NSF IIS-1321119. This video uses materials under a Creative Common license or with the owner's permission, as detailed at the end.