INTRODUCTION:
In the short time since its launch, Sun Microsystems's Java Technology
has become almost synonymous with portable software that can be distributed
across the internet. Java's pre-eminent position is reinforced by the fact
that built-in support for its distribution format, the JVM, is now not
only part of every World Wide Web browser, but is starting to appear even
within operating systems.
This distribution of mobile code is achieved using platform neutral
byte codes which are contained in a unit referred to as a class. One
of the most important factors to consider for code mobility is the network
transmission performance. For applications running across the internet,
this factor could be quite indeterministic and could prove to be a bottleneck
in more than one situation. To reduce the dependency on the network performance
it may become necessary to achieve good compression of code before sending
down the wire.
Taking a look at the class file structure defined in the JVM specification
it becomes obvious that there is potential scope to reduce the file size
using compression techniques.
OVERVIEW:
Even though there are several structures within a java class which can
be compressed this exercise primarily focuses on compression of methods
( byte codes). The primary technique used here for compression
is based on patternization as suggested by [Code Compression; Jens Ernst,
etc..][Custom inst. Sets for code compression; Fraser, Proebsting].
The algorithm tries to match the input instructions with known instruction
patterns and substitutes the matched instructions with new specialized
intructions.
Post byte code compression, the compression algorithm further compresses
using the GZIP compression to achieve more than 50% compression on the
overall class file size.
Finally a general purpose file and URL class loader have been implemented
which can read compressed as well as uncompressed class files. All compressed
class files are passed through a decompressor to return the original class
bytes back to the JVM. One additonal noteworthy benefit is that,
as the compression algorithm changes the output class file structure(maintaining
the semantic structure) in such a way that only a proprietary class File
reader can read the class, we automatically also get "obfuscation" of the
class files.
GOALS:
-
Provide a byte code compression algorithm which will compress any java
class file. The algorithm can be just specific to only handle java class
files.
-
Further provide compression of the byte code compressed classes using general
purpose compression techniques like GZIP, etc., to achieve overall compression.
-
Provide a decompression algorithm which can handle java classes which are
just byte code compressed or both, byte code compressed and GZIP compressed.
-
Provide ways by which unnecessary debugging information can be eliminated
from class files.
-
Compare the results.
-
Create a Class file loader which can load the classes which are compressed
or uncompressed.
FEW PUBLISHED COMPRESSION METHODS:
There are several compression techniques available today and trade-offs
have to be made to choose one over the other. For instance some of the
better compression techniques are multi-pass resulting in more time spent
for compression and decompression.
I)
One compression technique suggested involves patternizing the input
[Proebsting; Fraser and Proebsting]. Patternization accepts an actual program
and proposes specialized instructions that might help compress that program.
The patterns replace each combination of operands with wildcards.
For example the code "FetchInt( AddrLocal[4])" generates the patterns:
1. FetchInt(*)
2. FetchInt(AddrLocal[*])
3. FetchInt(AddrLocal[4])
II)
[Jens Ernst, etc] proposes the above technique along with other compression
techniques to achieve a compression factor of about 5. They use the term
wire-format for the compressed code as they cannot be interpreted directly
and need to be decompressed before they can be used.
The technique suggested involves patternizing out all literals, form
one stream for all patterns and one for containing the literal operands
associated with each opcode or class of related opcodes, MTF code(discussed
below) each stream, and gzip the resulting stream in isolation.
MTF coding (Move-to-front) technique starts by replacing sequence elements
with their indices in a table the changes dynamically. The tables elements
are ordered such that the first element was the most recently accessed
element; after each new access, the accessed element is moved to the front
and all intermediate elements are shifted down one place. A sequence with
high spatial locality tends to yield a sequence of small indices, which
should compress well.
III)
[Franz, Kistler] suggest a different intermediate code representation
than the linear format seen in Java byte codes. This intermediate code
is referred to as "slim binaries". The slim binary representation is based
on abstract syntax trees and describes the actions of the original program
similar to a parse tree. This intermediate tree-representation is compressed
by merging isomorphic sub-trees, using a variant of Welchs classes LZW
algorithm that has been specifically adopted towards compressing program
trees.
ANALYSIS:
The JVM instruction set lends itself well for the technique suggested in
I) for two primary reasons:
-
The instruction set is small and mostly stack based and uses numbered "local
variables" to store results. There are number of instruction which involve
moving data onto the top of the stack, operating on them and returning
the results back to the top of stack. E.g.:
1. ALOAD_0 -> INVOKEVIRTUAL <operand> ; 2. ALOAD_0 -> ICONST_0
-> PUTFIELD <operand> ( Notation:: -> stands for "followed by" )
-
The JVM instruction is a single byte instruction allowing 255 possible
instructions. Only 201 instructions are currently being generated for use
in class files. This potentially allows us to create about 50 new instructions
based on patterns matched.
The technique suggested by III), even though quite attractive does not
lend itself well for the current assignment, where it is essential for
current JVMs in the market to be able to execute the code after decompression.
It has been designed for a virtual machine which can operate directly on
tree representations of the code.
BYTE CODE COMPRESSION USING Static Patterns:
The technique used here is similar to I) wherein patterns in the instruction
set are matched with templates and replaced with new instructions. It is
different from I) because rather than figuring out the repeating patterns
dynamically, the current implementation uses static templates (Found studying
many different disassembled class files). Similar to I) the technique
uses "operand specialization", factoring out the operands during template
matching. The use of having "static templates" makes the algorithm single
pass.
The compression technique can be best explained through a example. Consider
the following disassembled byte code shown below:
Method public void enable()
>> max_stack=2, max_locals=4 <<
0 ALOAD_0
1 GETFIELD #197 <Field Component.enabled:boolean>
4 iconst_1
5 if_icmpeq 38
8 ALOAD_0
9 ASTORE_1
10 aload_1
11 monitorenter
12 aload_0
13 iconst_1
14 putfield #197 <Field Component.enabled:boolean>
17 ALOAD_0
18 GETFIELD #176 <Field Component.peer:peer.ComponentPeer>
37 NEW #28 <CLASS JAVA.LANG.STRINGBUFFER>
40 DUP
A couple of the very commonly occurring instruction sequences is highlighted(
uppercase) in the sample code.
The compression technique basically deals with two types of instruction
sets:
-
Instructions using Numbered Variables.
-
Instructions accessing the constant pool.
Instructions using numbered Variables:
These are instructions that use variables to store intermediate values
during method execution. The variables are numbered from 0 , onwards.
These instructions can be further classified into 2 distinct types: One
set of Instr's using variables '0' through '3' and another set using variable
'4' upwards. The instructions using variables '0' through '3' includes
the variable number as part of the opcode itself, occupying only a single
byte. E.g. ILOAD_0, ILOAD_1, ILOAD_2, ILOAD_3. Instructions using variables
'4' onwards use a single byte operand to store the variable number.
Now consider the instruction sequence ALOAD_0 -> ASTORE_1 ( Notation:
-> stands for , "followed by"), highlighted in the sample code are instructions
which use numbered variables. The compressor matches this instruction sequence
using the following template: ALOAD_# -> ASTORE_# . Here # is any
numbered variable used in the instruction. The match results in the replacement
of the two instructions with a new instruction ALOAD_ASTORE, occupying
only a single byte.
By factoring out the numbered variable from the instructions, we can
see that a single instruction (ALOAD_ASTORE) matches a total of 16 different
combinations of ALOAD_# -> ASTORE_# . This factorization technique is very
useful given that only about 50 new instructions can be generated ( A different
approach where generation of new instructions of variable length, may also
have been possible, but not considered here ).
The compressor uses a separate stream to store all the factored out
numbered variables in the same sequence as they appear in the original
program. Now as all the numbered instructions only use variables 0 through
3 , only two bits are needed to store any given variable number.
So, for the considered instruction sequence using 2 bytes in the original
class, a single byte new instruction and 4 bits for storing the variable
numbers will be required. From this simple example, it can be observed
that only ½ a byte has been saved, but the idea can be extended
to match sequences containing more than 2 instructions, resulting in better
savings.
Instructions accessing the constant pool:
There are many instructions within the JVM instruction set which use a
16 bit unsigned integer index as an operand pointing to an entry in the
constant pool.
The following about the constant pool are worth noting:
-
The entries in the constant pool can be one of twelve different types.
Entry types like FieldRef and MethodRef contain values which in turn
point to other entries like Class and Name_and_type.
-
Studying typical class files suggested that the references made by the
constant pool accessing instructions point to the first few hundred entries
of the constant pool, even though the total number of constant pool entries
might be quite large.
-
A large number of class files of typical java applications are relatively
small and have less than 255 constant pool entries.
The JVM instructions accessing the constant pool use a 16 bit integer index
into the constant pool irrespective of the size of the constant pool. The
compressor determines the size of the constant pool in the original program
and substitutes these indexes with a 8 bit integer index when all the operands
of constant pool accessing instructions is less than 255 ( Note: The actual
number of entries in the constant pool may be much larger).
Consider the instruction sequence NEW <index> -> DUP in the sample
program. The compressor matches this instruction sequence using the following
template: NEW <xx>-> DUP . The match results in the replacement
of the two instructions consuming 4 bytes with a new instruction NEW_DUP,
occupying only a single byte. The constant pool index <xx> is factored
out into a separate stream for constant pool indexes and stored as a single
byte. This technique results in 50% saving.
The below table shows the current patterns (templates) the compressor
supports along with the new instruction generated plus the extra stream
information corresponding to constant pool indexes and variable numbers.
Current Byte Code Patterns matched (All instructions are
single byte)
| Pattern |
New Instruction |
o/p to Constant Pool Idx Stream |
o/p to Numbered Variable Stream |
|
|
|
|
| ICONST_x -> ISTORE_x |
ICONST_ISTORE |
|
<x -> x> :: 4 bits |
| ILOAD_x -> ISTORE_x |
ILOAD_ISTORE |
|
4 bits |
| ALOAD_x ->ASTORE_x |
ALOAD_ASTORE |
|
4 bits |
| ISTORE_x->ILOAD_x |
ISTORE_ILOAD |
|
4 bits |
| ASTORE_x->ALOAD_x |
ASTORE_ALOAD |
|
4 bits |
ALOAD_x ->
GETFIELD yy |
ALOAD_GETFIELD |
1 byte |
2 bits |
ALOAD_x ->
INVOKEVIRTUAL yy |
ALOAD_
INVOKEVIRTUAL |
1 byte |
2 bits |
LDC yy ->
INVOKEVIRTUAL zz |
LDC_INVOKEVIRTUAL |
2 bytes |
|
ALOAD yy ->
INVOKEVIRTUAL zz |
ALOAD_
INVOKEVIRTUAL1 |
2 bytes |
|
| NEW yy -> DUP |
NEW_DUP |
1 byte |
|
ALOAD_x ->
PUTFIELD yy |
ALOAD_PUTFIELD |
1 byte |
2 bits |
ALOAD_x ->
INVOKESPECIAL yy |
ALOAD_
INVOKESPECIAL |
1 byte |
2 bits |
ALOAD_x ->
GETSTATIC yy |
ALOAD_GETSTATIC |
1 byte |
2 bits |
| ALOAD_x -> ICONST_x -> PUTFIELD yy |
ALOAD_ICONST_
PUTFIELD |
1 byte |
4 bits |
High Level Design:
Class Compressor Architecture:
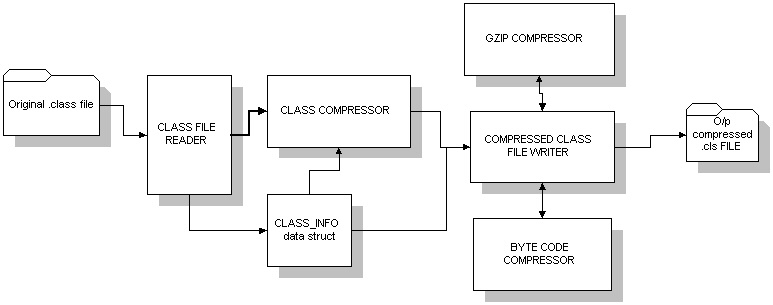
The class files which have structure as defined in the JVM specification
are compressed using a "Class Compressor". A "class file reader" reads
the entire class file, parses it into a container "Class_info". A Class_info
itself is a aggregation of components like FieldInfo, MethodInfo, etc(
Class diagram below shows the relationships). The "Class Compressor" delegates
the responsibility of actual compression to a "Compressed Class File Writer".
The methods are compressed using a "Byte Code Compressor" and the entire
compressed "Class Info" structure is further compressed using a GZIP compression
stream. The final compressed "Class Info" structure is streamed out a file
with a ".cls" extension.
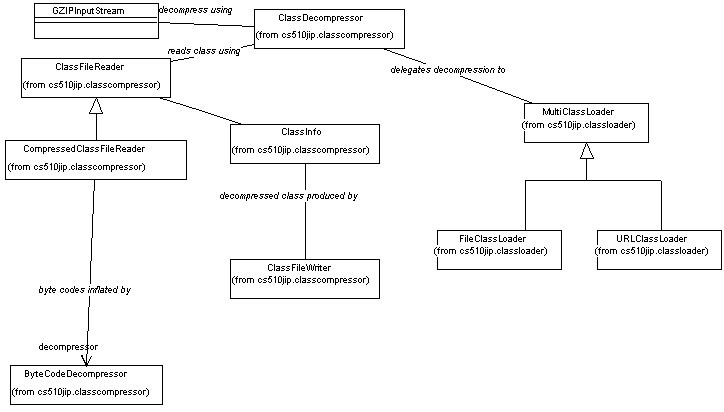
Class Decompressor Architecture:
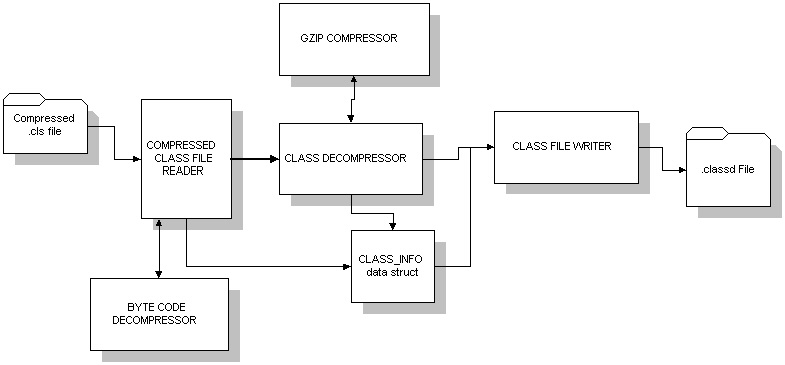
A "Compressed Class File Reader" can read compressed .cls files, parse
it, decompress it and create a "Class Info" structure. If the .cls
file is GZIP compressed, it is first read through a GZIP inflation stream.
The methods read are passed on to a "Byte Code Decompressor" and the inflated
methods are written on to "Class Info". Finally a "Class File Writer" is
used to write the "Class Info" data structure back to a file stream (.classd).
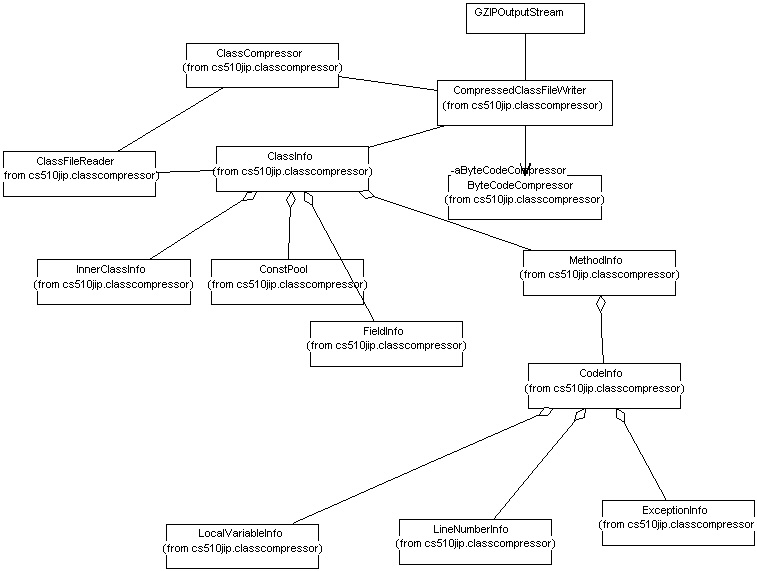
Class diagram 1: Class Compression:
The diagram below shows some of the important classes used for class compression
along with their relationships.
Class diagram 2: Class Decompression:
The diagram below shows some of the important classes used for class(.cls)
decompression along with their relationships.
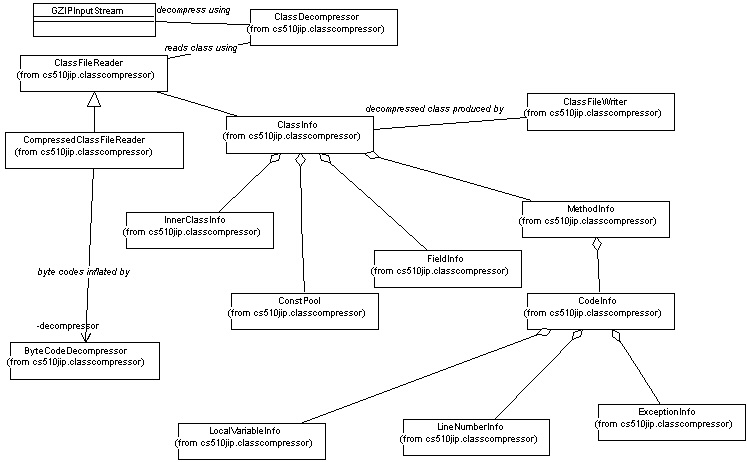
Class diagram 3: Compressed Class Loading:
Implementation Notes:
Most of the code for the Class File Reader and Writer was downloaded from
the world wide web. Few modifications and bug fixes had to be done.
The class CompressedClassFileReader was implemented ,overriding some
of the behaviour of ClassFileReader. It for instance, overrides "method
reading", uses a ByteCodeDecompressor to decompress the method byte code
and write the inflated byte code into ClassInfo.
Similarly class CompressedClassFileWriter overrides some of the behaviour
of ClassFileWriter. It for instance, overrides "method writing",
uses a ByteCodeCompressor to compress the method byte code and write the
deflated byte code into ClassInfo.
A trivial file and URL class loaders have been implemented which can
read compressed(.cls) or uncompressed(.class) files. The uncompressed classes
are in turn resolved using the primordial class loader, hence validating
the decompression.
The entire implementation is done using 'java' and has been implemented
without catering to any specific performance goals.
..........
To install and execute the Class compressor and Compressed Class file
loader, read the User's guide.
Results:
Byte Code compression Results( all figures in bytes)
| Class |
Original Size ( bytecode) |
Compressed byte code size
(bytecode + operand stream) |
% change |
| BoundObject.class |
4079 |
2537 + 613 = 3150 |
|
| Applet.class |
255 |
179+32 = 211 |
|
| Column.class |
1091 |
715+148 = 863 |
|
| Animation.class |
1173 |
801+157 = 958 |
|
| Assignment.class |
464 |
266+74 = 340 |
|
| AWTEventMulticaster.class |
1250 |
990+109 = 1099 |
|
| ClassFileReader.class |
2911 |
2534+154 = 2688 |
|
| ClassFileWriter.cls |
2825 |
2404+175 = 2579 |
|
Overall Class Compression Results ( all figures
in bytes)
| Class |
Original size |
Just bytecode compression |
Bytecode + GZIP + removal of debug data |
PKZIP only |
| BoundObject.class |
13899 |
12974 |
4198 |
5986 |
| Applet.class |
2713 |
2673 |
1071 |
1240 |
| Column.class |
9352 |
9128 |
2359 |
2860 |
| Animation.class |
6576 |
6365 |
2956 |
3656 |
| Assignment.class |
3378 |
3258 |
807 |
967 |
| AWTEventMulticaster.class |
7286 |
7139 |
1934 |
2406 |
| ClassFileReader.class |
10919 |
10703 |
3526 |
4739 |
| ClassFileWriter.class |
14175 |
13933 |
3759 |
6210 |
Future Enhancements:
-
Written in a native language such as 'C', to achieve better performance.
-
Change the ByteCode compression algorithm to generate patterns dynamically
and suggest new instructions.
-
Only about 15 new instructions are currently being generated. At least
30 new instructions, matching patterns could be added to the Byte
code compressor.
-
Consider packaging several class structures into a single compact structure.
-
Compress all the other structures within a class, to achieve good overall
compression.
-
etc..
Conclusion:
Byte code happens to constitute only about 10% to 20% of the overall class
file size. So even a 50% compression would only result in a 5 to 10% compression
of the overall class file size. So it is very essential to compress all
the other structures of the class file to achieve good compression ratio's.
Constant pool constitutes about 60% of the total class file size, and
its structure is ideal for compression.
For instance:
The tag bytes, one byte for each entry could be literally eliminated
by ordering the constant pool entries according to their type.
It is filled with UTF strings with many repeating string's like the
package name 'java.lang...', which could be reduced.
Roughly about 10% of the class size is consumed by debugging information.
This could be eliminated for production systems.
References:
[1] Christopher Fraser and Todd Proebsting, "Custom Instruction sets for
Code Compression", Unpublished Technical report, available in http://www.cs.arizona.edu/people/todd/papers/pldi2.ps
[2] Jens Ernst(Univ. of Arizona), Christopher Fraser(Microsoft Research),
etc,; "Code Compression".; ACM SIGPLAN'97
[3] Thomas Kistler and Micheal Franz, "A Tree based alternative to Java
Byte-Codes"; UC Irvine.
[4] The Java Virtual Machine Specification, Sun Microsystems.
[5] Thomas Kistler and Micheal Franz, "Slim Binaries"; UC Irvine.
[6] Micheal Franz, "Adaptive Compression of Syntax Trees and Iterative
Dynamic Code Optimization: Two basic technologies for Mobile-Object systems.";
UC Irvine.
================================================================================