![\begin{code}TYPE IARRAY IS ARRAY OF INTEGER;
PROCEDURE f(x:INTEGER,y:INTEGER) IS...
... IARRAY, w: INTEGER
.
.
.
f(3,w); ... g(a,a); ... f(17+5,a[3]);
.
.
.
\end{code}](img14.gif)
![]() Do we pass addresses (l-values) or contents (r-values) of variables?
Do we pass addresses (l-values) or contents (r-values) of variables?
![]() How do we pass actual values that aren't variables?
How do we pass actual values that aren't variables?
![]() What does it mean to pass an aggregate value like an array?
What does it mean to pass an aggregate value like an array?
Call-by-Value (i.e., r-value)
![]() Each actual argument is evaluated to a value before call.
Each actual argument is evaluated to a value before call.
![]() On entry, value is bound to formal parameter just like a local
variable.
On entry, value is bound to formal parameter just like a local
variable.
![]() Updating formal parameter doesn't affect actuals in calling procedure.
Updating formal parameter doesn't affect actuals in calling procedure.

![]() Simple; easy to understand!
Simple; easy to understand!
![]() Implement by copying.
Implement by copying.
Problems with Call-by-Value
![]() Can be inefficient if value is large.
Can be inefficient if value is large.
Example: Calls to dotp copy 20 doubles:

![]() Cannot affect calling environment directly.
(Often a good thing, but not always!)
Cannot affect calling environment directly.
(Often a good thing, but not always!)
Example: calls to swap have no effect:
![\begin{code}void swap(int i,int j) \{
int t;
t = i ; i = j; j = t;
\}
.
.
.
swap(a[p],a[q]);\end{code}](img18.gif)
![]() Can at best return only one result (as a value),
with same efficiency problems.
Can at best return only one result (as a value),
with same efficiency problems.
Call-by-Reference (i.e., l-value)
![]() Pass the address (l-value) of each actual parameter.
Pass the address (l-value) of each actual parameter.
![]() On entry, the formal is bound to the address, which must be
dereferenced to get value, but can also be updated.
On entry, the formal is bound to the address, which must be
dereferenced to get value, but can also be updated.
![]() If actual argument doesn't have an l-value (e.g., ``2 + 3''),
either:
If actual argument doesn't have an l-value (e.g., ``2 + 3''),
either:
- Evaluate it into a temporary location and pass address of temporary, or
- Treat as an error.
![]() Now swap, etc., work fine!
Now swap, etc., work fine!
![]() Accesses are slower.
Accesses are slower.
![]() Lots of opportunity for aliasing problems, e.g.,
Lots of opportunity for aliasing problems, e.g.,

![]() Call-by-value-result (a.k.a. copy-restore) addresses this problem, but
has other drawbacks.
Hybrid Methods
Call-by-value-result (a.k.a. copy-restore) addresses this problem, but
has other drawbacks.
Hybrid Methods
![]() Pascal, Ada, and similar languages allow the programmer
to specify which arguments are to be handled as call-by-value,
and which as call-by-reference. E.g., in Pascal, args are
cbv by default, and cbr if the VAR keyword is used.
Pascal, Ada, and similar languages allow the programmer
to specify which arguments are to be handled as call-by-value,
and which as call-by-reference. E.g., in Pascal, args are
cbv by default, and cbr if the VAR keyword is used.
![]() In C, programmers can take the l-value of a variable explicitly,
and pass that to obtain cbr-like behavior:
In C, programmers can take the l-value of a variable explicitly,
and pass that to obtain cbr-like behavior:
![\begin{code}swap(int *a, int *b) \{
int t;
t = *a; *a = *b; *b = t;
\}
...
swap (&a[p],&a[q]);\end{code}](img20.gif)
![]() C++ combines both these options:
C++ combines both these options:
![\begin{code}swap(int &a, int *b) \{
int t;
t = a; a = *b; *b = t;
\}
...
swap(a[p],&a[q]);\end{code}](img21.gif)
Mixing explicit and implicit pointers can be very confusing!
Records and Arrays
To understand argument passing of record and array types, must know what the language considers an r-value of these types to be!
![]() In Pascal, r-values of both arrays and records are the actual
contents. So passing a record or array by value means copying
the contents, whereas passing by reference (VAR parameter) doesn't.
In Pascal, r-values of both arrays and records are the actual
contents. So passing a record or array by value means copying
the contents, whereas passing by reference (VAR parameter) doesn't.
![]() In PCAT, r-values of both records and arrays are pointers
to the actual contents. PCAT has only call-by-value, but this
doesn't actually cause copying, even for record or array values.
In PCAT, r-values of both records and arrays are pointers
to the actual contents. PCAT has only call-by-value, but this
doesn't actually cause copying, even for record or array values.
![]() In ANSI C/C++, struct r-values are the actual contents,
but array r-values are pointers to the contents.
In ANSI C/C++, struct r-values are the actual contents,
but array r-values are pointers to the contents.
In this example, no doubles are copied on call:
![\begin{code}typedef double vector[10];
double dotp(vector v, vector w) \{
doubl...
...d += v[i] * w[i];
return d;
\}
vector v1,v2;
double d1 = dotp(v1,v2);\end{code}](img22.gif)
Records and Arrays (continued)
To avoid copying C structures, must use pointers:

![]() These issue also affect assignment, of course.
These issue also affect assignment, of course.
Substitution
![]() Can often get the effect we want using substitution,
i.e., macro-expansion, e.g (in C):
Can often get the effect we want using substitution,
i.e., macro-expansion, e.g (in C):
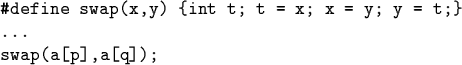
![]() BUT blind substitution is dangerous because of possible
``variable capture,'' e.g.,
BUT blind substitution is dangerous because of possible
``variable capture,'' e.g.,
![]()
expands to
![]()
Here ``t is captured'' by the declaration in the macro, and is
undefined at its first use.
![]() Really want ``substitution with renaming where necessary'' =
Algol-60's call-by-Name facility.
Really want ``substitution with renaming where necessary'' =
Algol-60's call-by-Name facility.
![]() Flexible, but potentially very confusing, and inefficient to implement.
Flexible, but potentially very confusing, and inefficient to implement.
![]() If language has no updatable variables (as in ``pure'' functional
languages), substitution gives a beautifully simple semantics for procedure calls.
If language has no updatable variables (as in ``pure'' functional
languages), substitution gives a beautifully simple semantics for procedure calls.
Procedures as Parameters
It can be handy to pass procedures as parameters to other procedures. This feature is supported by Pascal, etc. and by C.
Example (pseudo-PCAT)

Same Example in C

Using Local (Nested) Procedures
![]() Sometimes want to pass local functions as parameters.
Sometimes want to pass local functions as parameters.
Example: Improved version of sum:
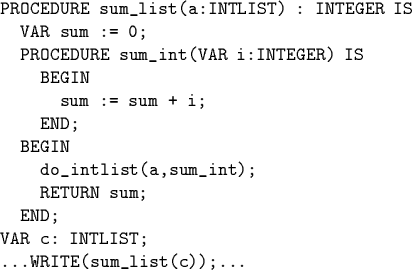
![]() Here sum_int operates on the value of variable sum,
which is neither local nor global.
Here sum_int operates on the value of variable sum,
which is neither local nor global.
![]() Solution: pass pair of (code-pointer,static-link) as
``value'' of procedure.
Solution: pass pair of (code-pointer,static-link) as
``value'' of procedure.
![]() Must guarantee that static link is still valid when procedure is called!
Must guarantee that static link is still valid when procedure is called!
![]() Cannot express this in C.
More Nested Procedures
Cannot express this in C.
More Nested Procedures
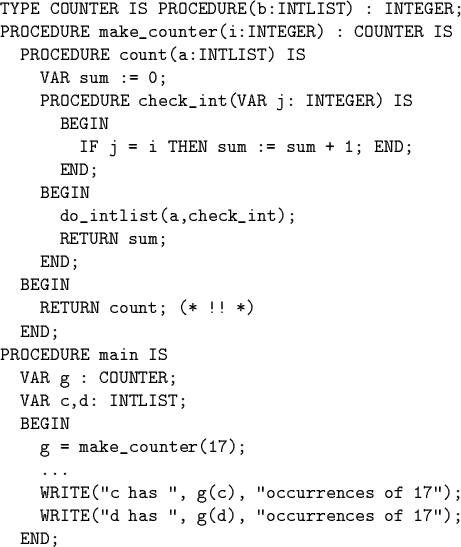
Example: Use iterator to count how many times specified integer occurs.

![]() Here check_int depends on the value of variable i,
which is neither local nor global.
Here check_int depends on the value of variable i,
which is neither local nor global.
![]() Going one step further, can be handy to treat procedure values just like
other values, e.g., to return them as function results or store
them into variables.
Going one step further, can be handy to treat procedure values just like
other values, e.g., to return them as function results or store
them into variables.
``First-class'' Procedures Example
Applying First-class Procedures
Example: Table-driven Command Processor
![\begin{code}TYPE COMMAND IS ENUMERATION
(SUMALL = 0, COUNT42S, COUNT101S, ...)...
...INTLIST)
IS
BEGIN
WRITE (''Answer is '', actions[command] (a));
END\end{code}](img32.gif)
![]() Often handy for ``call-backs'' from operating
system or window system.
Problems with first-class procedures
Often handy for ``call-backs'' from operating
system or window system.
Problems with first-class procedures
Consider activation tree for make_counter example:

Activation of make_counter is no longer live when
count is called!
If i is stored in activation record for make_counter and activation-record is stack-allocated, it will be gone at the point where check_int needs it!
To avoid this problem:
![]() Pascal prohibits ``upward funargs;'' procedure values can only
be passed downward, and can't be stored.
Pascal prohibits ``upward funargs;'' procedure values can only
be passed downward, and can't be stored.
![]() Some other languages only permit ``top-level'' procedures
to be manipulated as procedure values (in C, this means all
procedures!).
Some other languages only permit ``top-level'' procedures
to be manipulated as procedure values (in C, this means all
procedures!).
Heap Storage for Procedure Values
![]() Languages supporting first-class nested procedures
(e.g., Lisp, Scheme, ML, Haskell, etc.) solve problem by
using heap to store variables like i.
Languages supporting first-class nested procedures
(e.g., Lisp, Scheme, ML, Haskell, etc.) solve problem by
using heap to store variables like i.
![]() Simple solution: Just put all activation records
in the heap to begin with! (Garbage collection is a must!)
Simple solution: Just put all activation records
in the heap to begin with! (Garbage collection is a must!)
![]() More refined solution: Represent procedure values
by a heap-allocated ``closure'' record, containing the
procedure's code pointer and
values of the non-local variables referenced by the procedure.
More refined solution: Represent procedure values
by a heap-allocated ``closure'' record, containing the
procedure's code pointer and
values of the non-local variables referenced by the procedure.
![]() Involves taking copies of the values of
non-local variables, so only works when values are immutable.
Involves taking copies of the values of
non-local variables, so only works when values are immutable.
![]() Can always introduce extra level of indirection to
achieve this.
Can always introduce extra level of indirection to
achieve this.
Functional Programming
What does functional mean? Two main senses:
![]() Programs consist of functions with no side effects.
Programs consist of functions with no side effects.
![]() Functions are supported as ``first-class'' values.
Functions are supported as ``first-class'' values.
Claim: functional programs are:
![]() clearer;
clearer;
![]() easier to get right;
easier to get right;
![]() easier to test;
easier to test;
![]() easier to transform;
easier to transform;
![]() easier to parallelize;
easier to parallelize;
![]() easier to prove things about.
easier to prove things about.
Important examples:
![]() Lisp, Scheme (``strict'', dynamically typed, impure)
Lisp, Scheme (``strict'', dynamically typed, impure)
![]() Standard ML, CAML (``strict'', statically typed, impure)
Standard ML, CAML (``strict'', statically typed, impure)
![]() Haskell, Gofer (``lazy'', statically typed, pure)
Haskell, Gofer (``lazy'', statically typed, pure)
ML Example: Dictionaries with Sorted Lists

Features
![]() Identifiers denote values, not changeable variables.
Identifiers denote values, not changeable variables.
![]() insert is a function that returns a new list
without changing its argument!
insert is a function that returns a new list
without changing its argument!
![]() Control structure is recursion, not iteration.
Control structure is recursion, not iteration.
![]() Definition of lists is built into language; other similar
data structures can be user-defined.
Definition of lists is built into language; other similar
data structures can be user-defined.
![]() List nodes (and other data structures)
are tested and destructured using pattern matching.
Why bother?
List nodes (and other data structures)
are tested and destructured using pattern matching.
Why bother?
Functions can't have side-effects. Therefore, they can't have dangerous, hidden side-effects!
Consider this C fragment:

Will s be true? It depends whether f modifies t!
Compare this functional code:
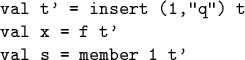
Here s must be true, because f can't modify
it's argument (or anything else)! Also compare:
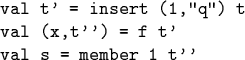
It's testable.
![]() True functions can always be tested separately.
True functions can always be tested separately.

If appendx is wrong, then its definition is wrong, or find or delete or insert must be wrong.
The problem can't be due to a hidden interaction between find, delete, and/or insert.
Any coupling between functions must be made explicit in their arguments or return values.
This helps discourage coupling!
(In principle, debugging by divide and conquer can even be automated.
In practice, conventional trouble-shooting is much easier.)