(![]() Really ``improvement'' rather than ``optimization;'' results are seldom optimal.)
Really ``improvement'' rather than ``optimization;'' results are seldom optimal.)
![]() Remove inefficiencies in user code and (more importantly) in compiler-generated code.
Remove inefficiencies in user code and (more importantly) in compiler-generated code.
![]() Can be applied at several levels, chiefly intermediate or assembly code.
Can be applied at several levels, chiefly intermediate or assembly code.
![]() Can operate at several levels:
Can operate at several levels:
- ``Peephole'' : very local IR or assembly
- ``Local'' : within basic blocks
- ``Global'' : entire procedures
- ``Interprocedural'' : entire programs (maybe even multiple source files)
![]() Theoretical tools: graph algorithms, control and data flow analysis.
Theoretical tools: graph algorithms, control and data flow analysis.
![]() Practical tools: few.
Practical tools: few.
![]() Most of a serious modern compiler is devoted to optimization.
Most of a serious modern compiler is devoted to optimization.
Peephole Optimizations
![]() Look at short sequences of statements (in IR or assembly code)
Look at short sequences of statements (in IR or assembly code)
![]() Correct inefficiencies produced by excessively local code generation strategies.
Correct inefficiencies produced by excessively local code generation strategies.
![]() Repeat!
Repeat!
![]() Redundant instructions
fmovd
fmovd
Redundant instructions
fmovd
fmovd
![]() Unreachable code
Unreachable code
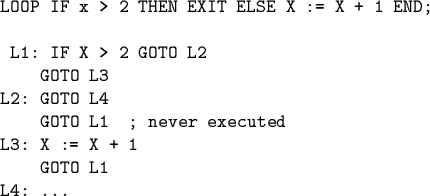
![]() Flow-of-control fixes: remove jumps to jumps, e.g.,
Flow-of-control fixes: remove jumps to jumps, e.g.,
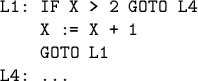
More Peephole Optimizations
![]() Algebraic Simplification
Algebraic Simplification
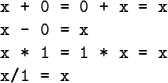
![]() Strength Reduction
Strength Reduction
Target hardware may have cheaper ways to do certain operations.
E.g., multiplication or division by a power of 2 is better done by shifting.
umul
![]() Use of machine idioms
Use of machine idioms
Target hardware may have quirks/features that make certain sequences faster: set 372, add Local (Basic Block) Optimizations
![]() Typically applied to IR,
after addressing is made explicit, but
before machine dependencies appear.
Typically applied to IR,
after addressing is made explicit, but
before machine dependencies appear.
![]() Most important: Common Subexpression Elimination (CSE)
Most important: Common Subexpression Elimination (CSE)
![]()
Avoid duplicating the code for j+1 or the addressing code for a[i].
![]() Copy Propagation
Copy Propagation
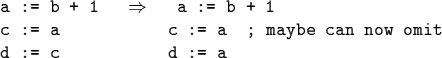
![]() Algebraic Identities
Algebraic Identities
E.g., use associativity and commutativity of +
![]()
![]() Iterate! Optimizations enable further optimizations.
Iterate! Optimizations enable further optimizations.
![]() Primary technique: build directed acyclic graph (DAG)
for basic block.
Primary technique: build directed acyclic graph (DAG)
for basic block.
CSE Example
![\begin{code}Source: i := j + 1
a[i] := b[i] + j + 1
\par Naive IR: After CSE:
\...
...21
t23 := t18 + t22 t23 := t18 + t10 ; &(a[i])
*t23 := t17 *t23 := t17\end{code}](img21.gif)
Global (Full Procedure) Optimization
Loop optimizations are most important.
![]() Code motion: ``hoist'' expensive calculations above the loop.
Code motion: ``hoist'' expensive calculations above the loop.
![]() Use induction variables and reduction in strength. Change only one
index variable on each loop iteration, and choose one that's cheap to change.
Use induction variables and reduction in strength. Change only one
index variable on each loop iteration, and choose one that's cheap to change.
Also continue to apply CSE, copy propagation, dead code elimination, etc. on global scale.
Based on flow graph:
![]() nodes are basic blocks
nodes are basic blocks
![]() edge from bb A to bb B if B can be executed immediately after A.
edge from bb A to bb B if B can be executed immediately after A.
Example: Computing dot product (assuming i,a local; b,c global). Local CSE already performed within basic blocks.
![\begin{code}a = 0;
for (i = 0; i < 20; i++)
a = a + b[i] * c[i];
return a;
\end{code}](img22.gif)
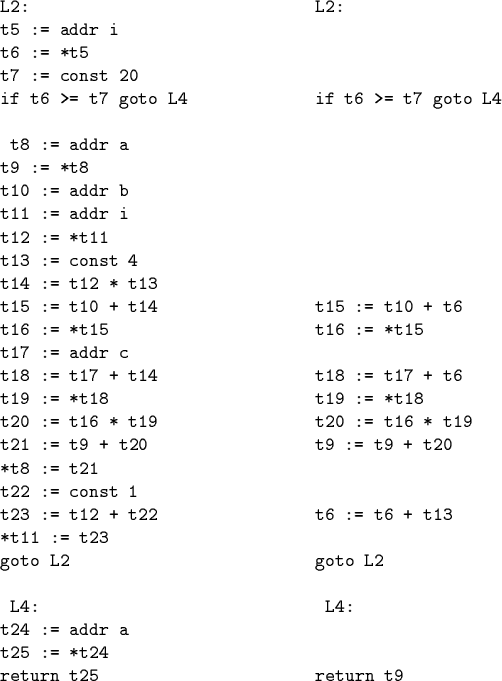
IR for Dot Product
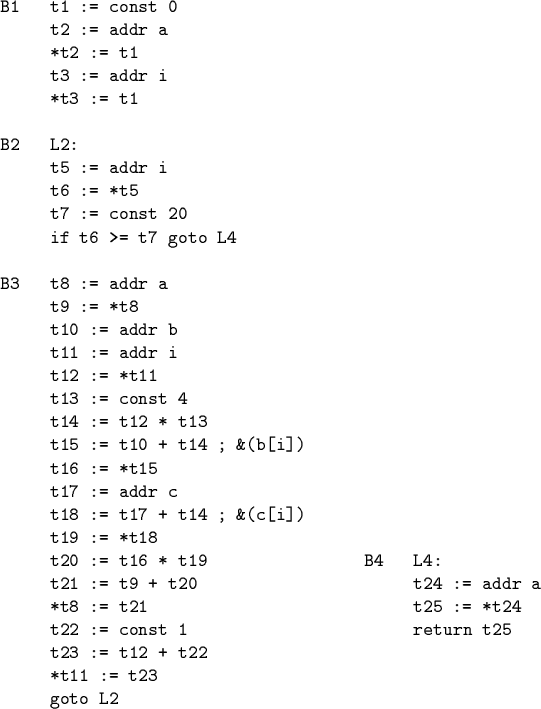
Example: effects of global optimization
![]() Promote locals a and i to registers.
Promote locals a and i to registers.
![]() Induction variable: replace i with i*4, thus
reducing strength of per-loop operation; adjust test accordingly.
Induction variable: replace i with i*4, thus
reducing strength of per-loop operation; adjust test accordingly.
![]() Hoist all constants out of loop.
Hoist all constants out of loop.