Convert source file characters into token stream.
Remove content-free characters (comments, whitespace, ...)
Detect lexical errors (badly-formed literals, illegal characters, ...)
Output of lexical analysis is input to syntax analysis.
Could just do lexical analysis as part of syntax analysis.
But choose to handle separately for better modularity, portability.
Idea: Look for patterns in input character sequence, convert to tokens with attributes, and pass them to parser in stream.
Lexical Analysis Example
| Pattern | Token | Attribute |
| if | IF | |
| else | ELSE | |
| then | THEN | |
| := | ASSIGN | |
| = or < or > | RELOP | enum |
| letter followed by letters or digits | ID | symbol |
| digits | NUM | int |
| chars between double quotes | STRING | string |
Source code:
![]()
| Lexeme | Token | Attribute |
| if | IF | |
| x | ID | "x" |
| > | RELOP | GT |
| 17 | NUM | 17 |
| then | THEN | |
| count | ID | "count" |
| := | ASSIGN | |
| 2 | NUM | 2 |
| else | ELSE | |
| "bad!" | STRING | "bad!" |
More Details
A token describes a class of character strings with some distinguished meaning in language.
![]() May describe unique string (e.g., IF, ASSIGN)
May describe unique string (e.g., IF, ASSIGN)
![]() or set of possible strings, in which case an attribute is needed to indicate which.
or set of possible strings, in which case an attribute is needed to indicate which.
(Tokens are represented as elements of an enumeration.)
A lexeme is the string in the input that actually matched the pattern for some token.
Attributes represent lexemes converted to a more useful form, e.g.,:
![]() strings
strings
![]() symbols (like strings, but perhaps handled separately)
symbols (like strings, but perhaps handled separately)
![]() numbers (integers, reals, ...)
numbers (integers, reals, ...)
![]() enumerations
enumerations
Whitespace (spaces, tabs, new lines, ...) and comments just disappear!
Stream Interface
Could convert entire input file to list of tokens/attributes.
But parser needs only one token at a time, so use stream instead:
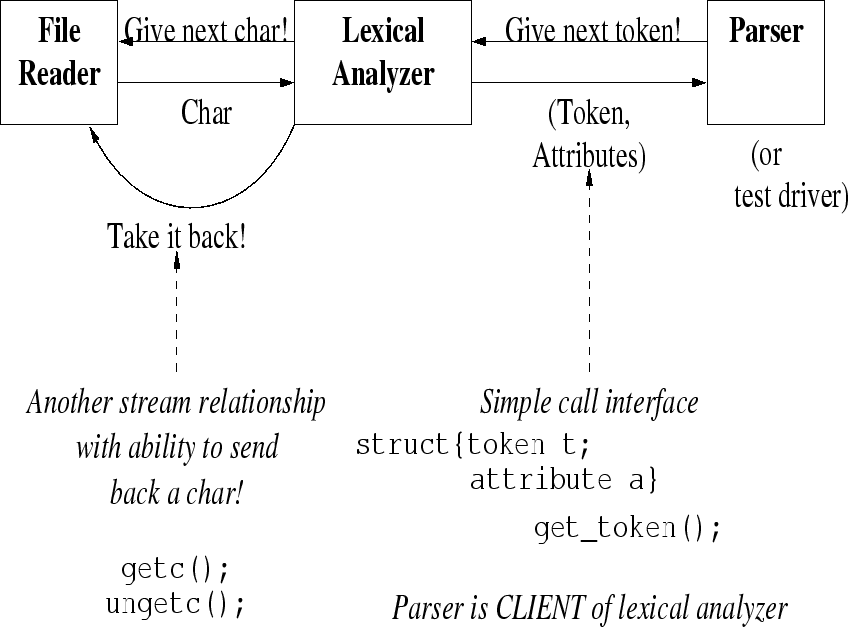
Hand-coded Scanner (in Psuedo-C)

Efficient! Easy to get wrong!
Note intermixed code for input, output, patterns, conversion.
Hard to specify! (esp. patterns). Example
How can we formalize this pattern description?
``An identifier is a letter followed by any number of letters or digits.''
![]() Exactly what is a letter?
Exactly what is a letter?

![]() Exactly what is a digit?
Exactly what is a digit?
![]()
![]() How can we express ``letters or digits'' ?
How can we express ``letters or digits'' ?
![]()
![]() How can we express ``any number of'' ?
How can we express ``any number of'' ?
![]()
![]() How can we express ``followed by'' ?
How can we express ``followed by'' ?
![]()
Regular Expressions
A regular expression (R.E.) is a concise formal characterization of a regular language (or regular set).
Example: The regular language containing all IDENTs is described by the regular expression
![]()
where ``![]()