An interpreter for a language L is a program PL' that given
![]() a description of a program QL (written in L), and
a description of a program QL (written in L), and
![]() an input I
an input I
behaves like QL on I.
L is the source language.
L', in which the interpreter is written, is the implementation language.
There are many possibilities for L' (including L itself!), but typically it will be a high-level language like C, Lisp, etc.
Important point is that PL' is generic: it should work for any possible program QL.
Examples
(Note: any language may be interpreted, but some usually are.)
BASIC, Pascal (via PCODE), Unix shells / PERL / Awk / TCL, Java, etc.
Pros and Cons
+ Easier to write than compiler; leverages high-level features of implementation language.
+ No compilation time overhead for users of source language; code-test-debug can be much quicker.
+ Portable, assuming implementation language is.
+ Provides a semantics, relative to implementation language.
- Interpretation is slower than running compiled code, mainly because decoding and dispatch are done in software, and because (ordinarily) very little optimization is done.
Continuum of possibilities between source interpretation and translation to machine code:
![]() Many systems translate source language to some intermediate language
and then interpret that.
Many systems translate source language to some intermediate language
and then interpret that.
![]() Hardware processors can be viewed as ``interpreting'' machine code instructions
(esp. if hardware is microcoded).
Hardware processors can be viewed as ``interpreting'' machine code instructions
(esp. if hardware is microcoded).
![]() Can build-special purpose hardware processors
for specific languages (e.g., LISP machines, Java chips).
Can build-special purpose hardware processors
for specific languages (e.g., LISP machines, Java chips).
Defining Interpreters Using Attribute Grammars
Like other language processing, convenient to define interpreters using grammatical syntax framework.
As first step, can define interpreter using an attribute grammar.
Approach similar to semantics definitions, but instead of computing a translation (to machine code, functions, etc.), actually compute the value of the program within the grammar.
Thus we use a.g. formalism as our ``implementation language.''
(Next step will be to encode the a.g. into a ``real'' language, like C.)
Need to use both synthesized and inherited attributes. Review of Attribute Grammars
Attribute Grammars (a.k.a. ``syntax-directed definitions'') allow convenient, concise definition of calculations on recursive structures.
Calculations are specified by describing their local behavior at parse tree nodes; structure of parse tree defines global shape of computation.
![]() Attach rules (a.k.a. ``attribute equations'') to grammar productions.
Attach rules (a.k.a. ``attribute equations'') to grammar productions.
![]() Rules compute attribute values at corresponding parse tree
node based on attribute values at
- parent nodes (inherited attributes), and/or
- child nodes (synthesized attributes)
Rules compute attribute values at corresponding parse tree
node based on attribute values at
- parent nodes (inherited attributes), and/or
- child nodes (synthesized attributes)
Example:
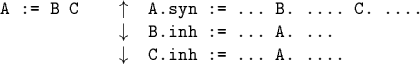
![]() Terminals may have ``built-in'' attributes (think of them as
being synthesized automatically).
Terminals may have ``built-in'' attributes (think of them as
being synthesized automatically).
![]() Types of attributes and form of rules vary widely.
Types of attributes and form of rules vary widely.
A.G. Definitions are ``Self-Checking''
Must remember to define all needed attributes.
![]() If S.inh is an inherited attribute, it must be defined each
time S appears in any grammar production right-hand side.
If S.inh is an inherited attribute, it must be defined each
time S appears in any grammar production right-hand side.
![]()
![]() If S.syn is a synthesized attribute, it must be defined each
time S appears as a grammar production left-hand side.
If S.syn is a synthesized attribute, it must be defined each
time S appears as a grammar production left-hand side.
![]()
Functional Attribute Grammars
Life is much nicer if we restrict the right-hand sides of attribute rules to be pure functions, i.e., calculations with no side-effects, because then
![]() The ``result'' of evaluation is just the value of the root node's synthesized
attributes.
The ``result'' of evaluation is just the value of the root node's synthesized
attributes.
![]() Evaluation can occur in any order consistent with data dependencies
among attribute rules.
Evaluation can occur in any order consistent with data dependencies
among attribute rules.
Must avoid circularities in rules, e.g.:
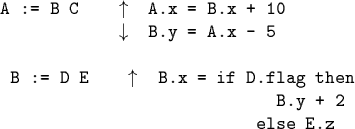
Precise definition of circularity can be subtle.
Simple Expression Language with Local Binding

Example:
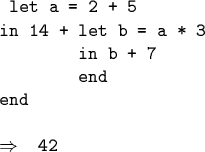
Attribute Grammar for Interpretation

Attribute Grammar (Cont.) Attributes:
Terminal NUM has .num attribute (number)
Terminal VAR has .var attribute (string)
Terminals '+','-',let,'=',IN,END have no attributes.
Non-terminal exp has - inherited env attribute (dictionary)
- synthesized val attribute (number)
A dictionary is a (functional) abstract data type supporting the following primitives:
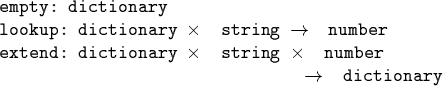
Imperative Evaluation Strategies
Functional attribute grammars have nice properties, but can make it awkward to deal with imperative features of languages, such as input/output and assignment statements.
Alternative: fix the evaluation order of attributes, so that we can safely include imperative statements (side effects) in the ``attribute equations'' section.
Default order: depth-first, left-to-right, but must obey data dependencies.
![]() First evaluate children's inherited attributes.
First evaluate children's inherited attributes.
![]() Then recursively evaluate children, obtaining their synthesized attributes.
Then recursively evaluate children, obtaining their synthesized attributes.
![]() Finally evaluate own synthesized attributes.
Finally evaluate own synthesized attributes.
![]() Can perform side-effects at any point specified (no standard way to express
this, though.)
Can perform side-effects at any point specified (no standard way to express
this, though.)
Example
Add variable update (via an update primitive for the dictionary ADT) and printing (via a write primitive).

Implementing Imperative Attribute Grammars
It is easy to turn imperative attribute grammars into recursive descent C programs that process tree data structures. (Type-checker was one example.)
![]() Each nonterminal N gets corresponding C function N.
Each nonterminal N gets corresponding C function N.
![]() Inherited attributes of N become extra arguments to the function N
Inherited attributes of N become extra arguments to the function N
![]() Synthesized attributes of N become
return values from the function N.
Synthesized attributes of N become
return values from the function N.
![]() Follow evaluation order described previously.
Follow evaluation order described previously.
![]() Side effects are executed wherever encountered.
Side effects are executed wherever encountered.
C version of Example
First the data structure:
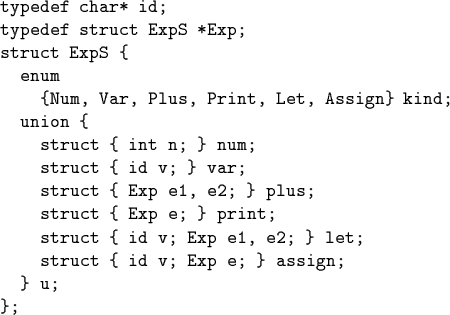
Assume suitable operations on environments and I/O:
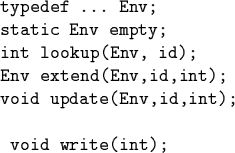
C version (Cont.)
The actual evaluation code:
